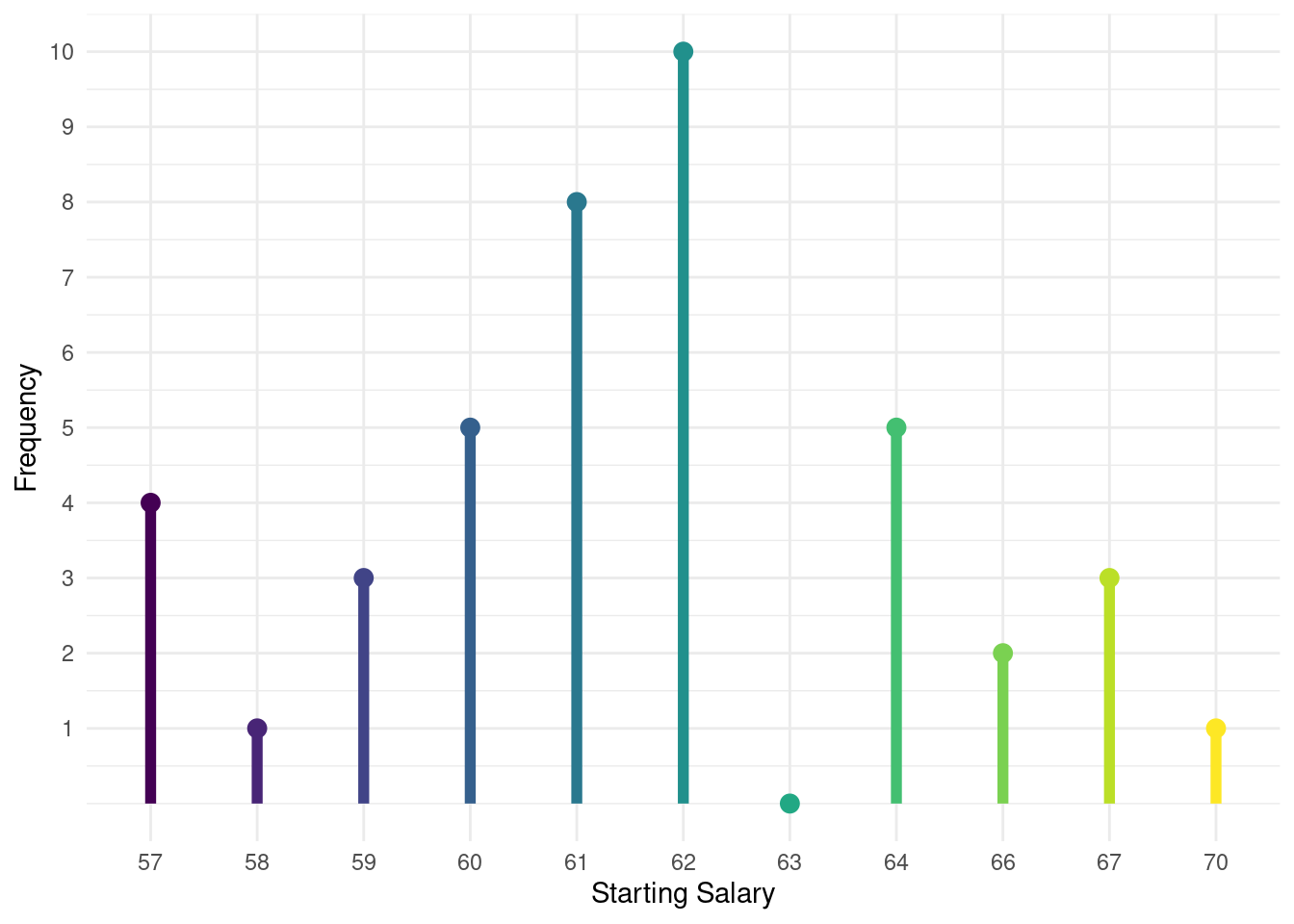
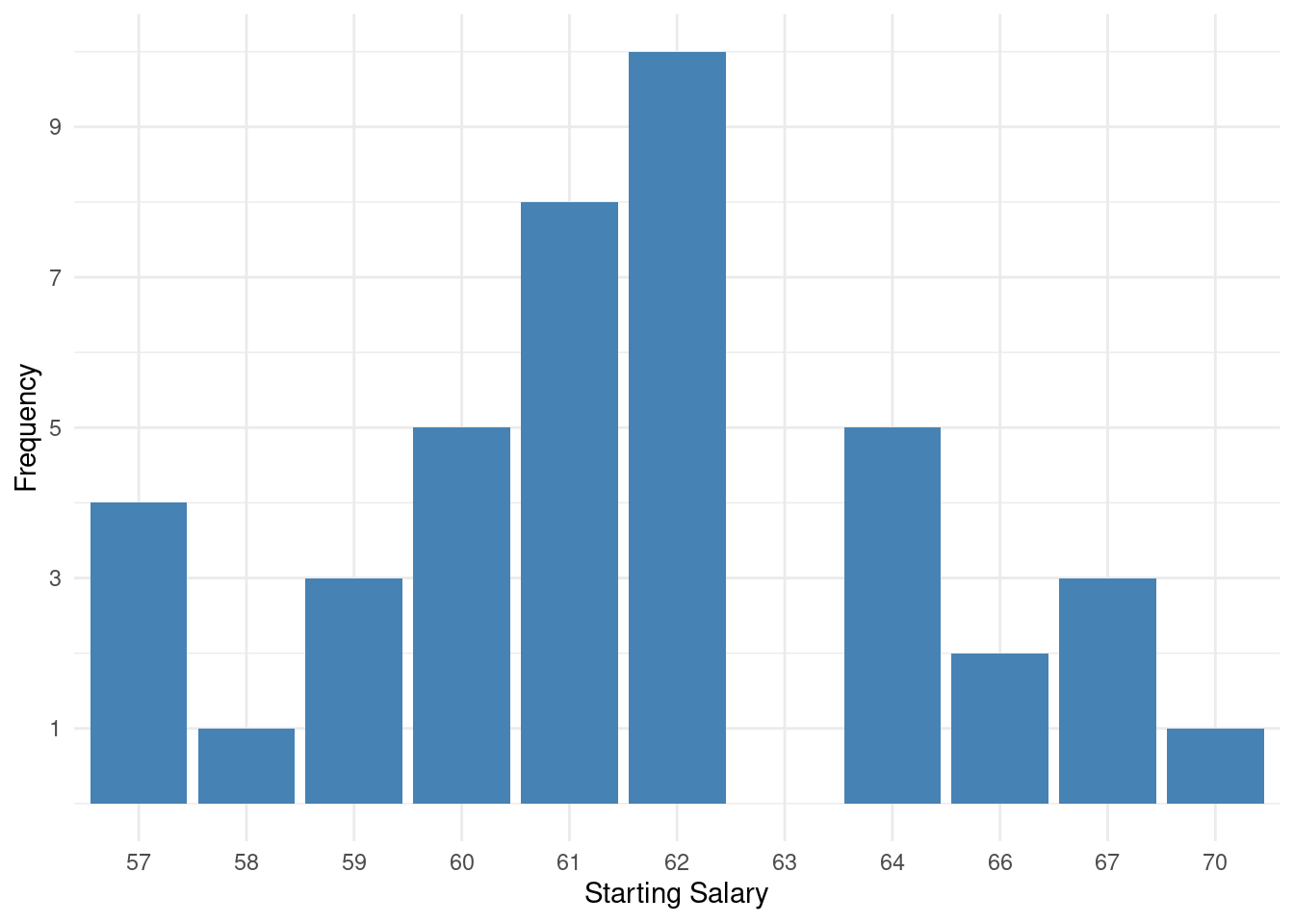
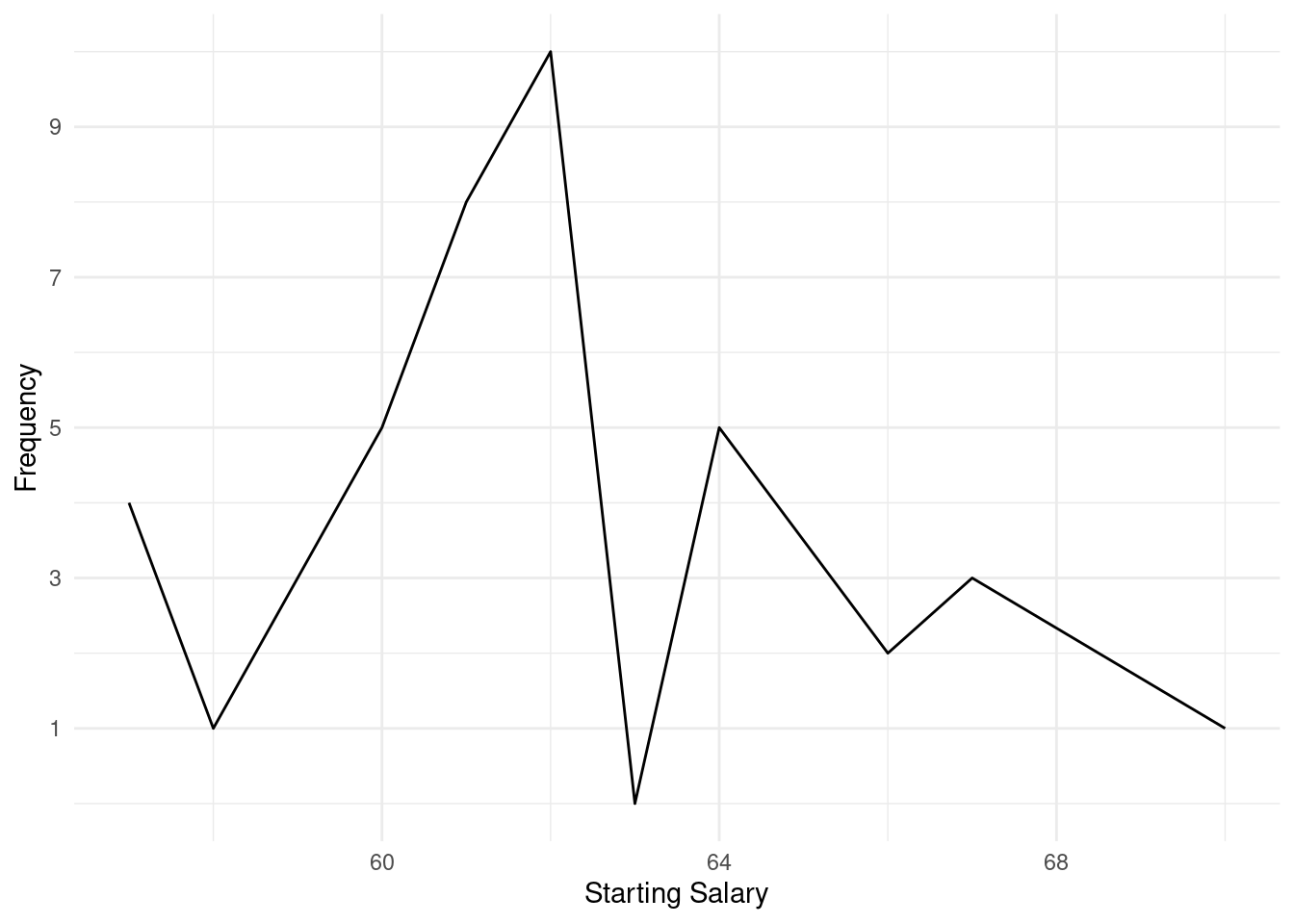
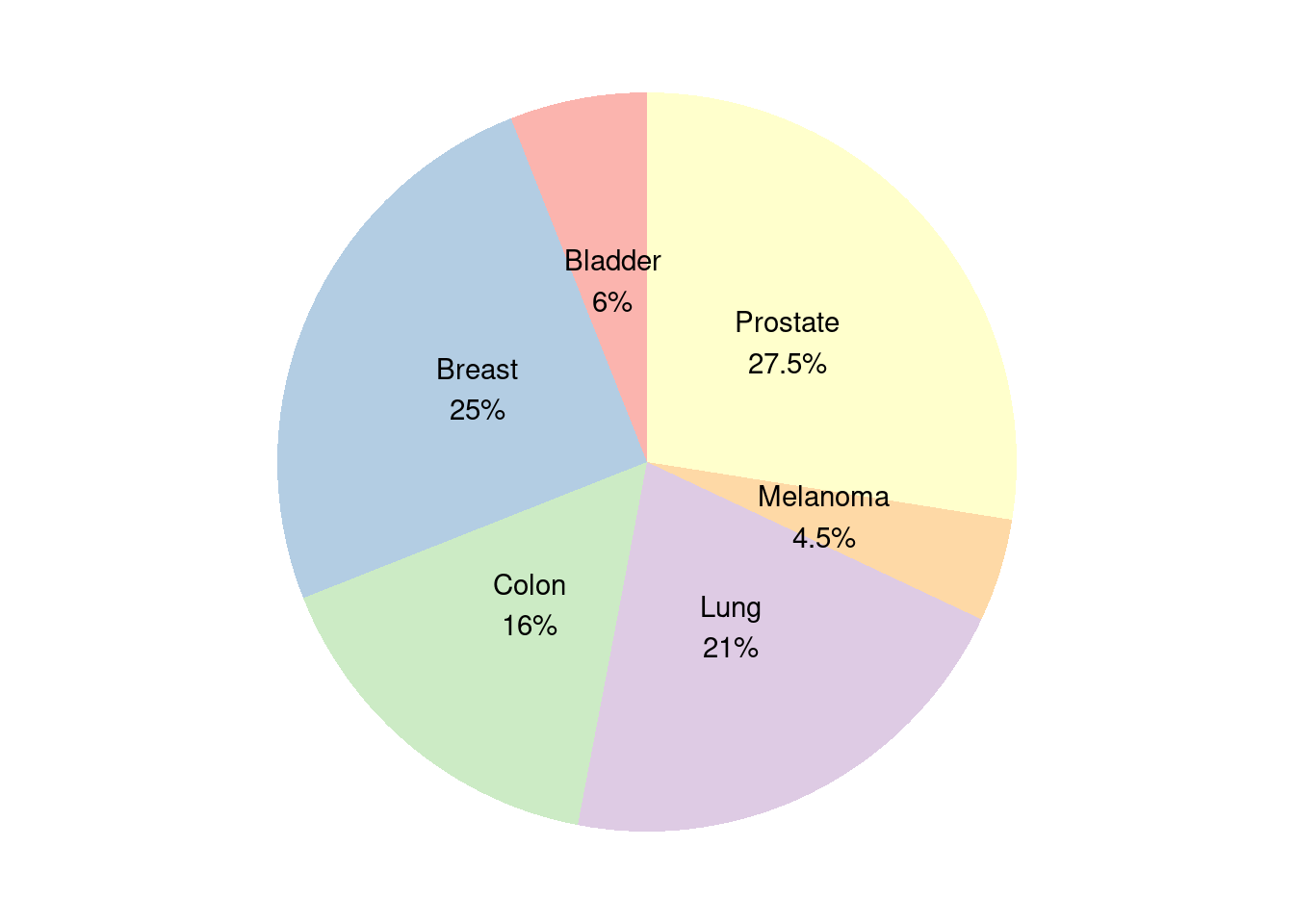
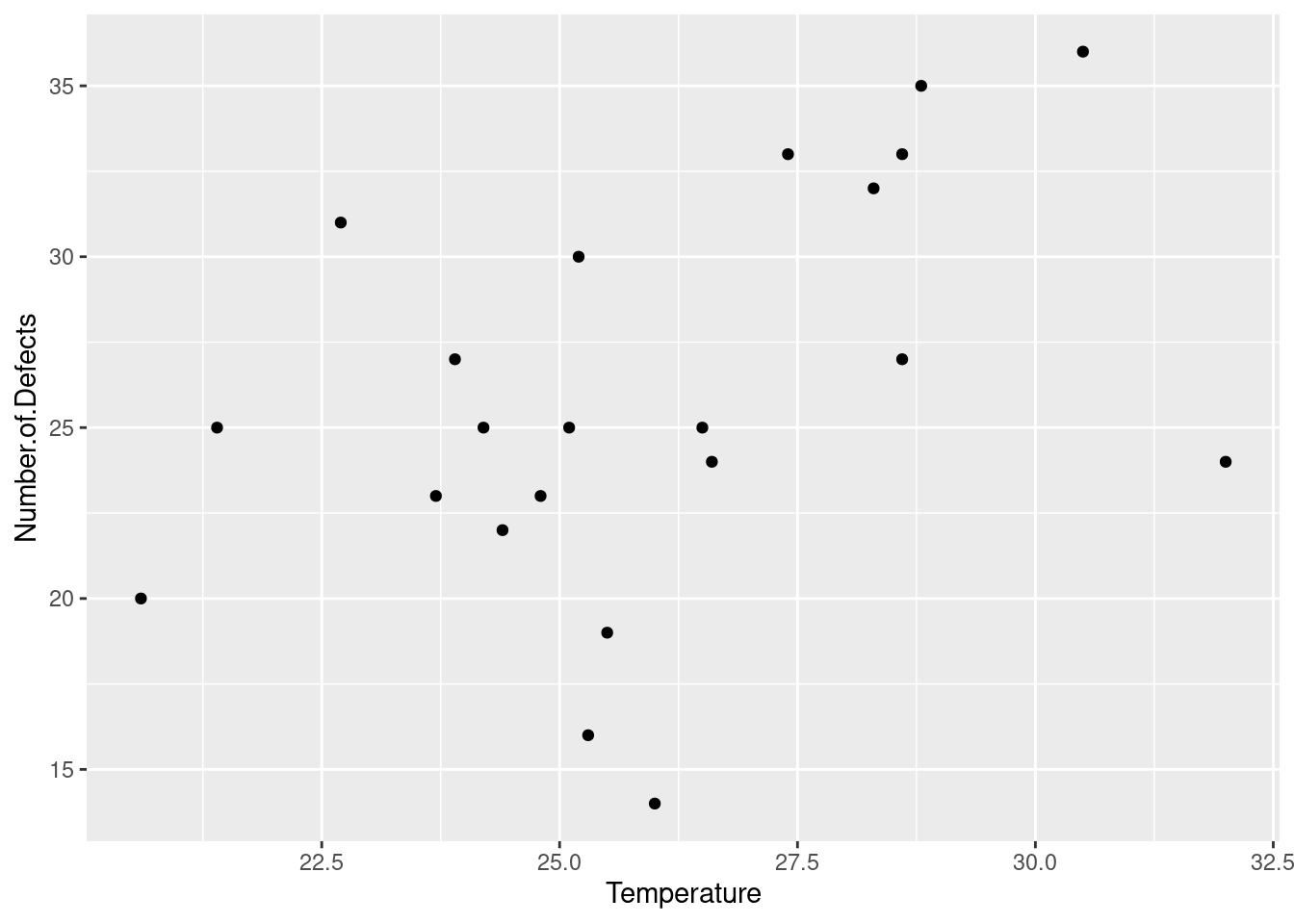
表格 2.5: 1961年~1990年,美国指定城市的每日最低气温表。数据来源:Source: U.S. National Oceanic and Atmospheric Administration, Climatography of the United States, No. 81。
State
Station
Jan.
Feb.
Mar.
Apr.
May
June
July
Aug.
Sept.
Oct.
Nov.
Dec.
Annual.avg.
AL
Mobile
40.0
42.7
50.1
57.1
64.4
70.7
73.2
72.9
68.7
57.3
49.1
43.1
57.4
AK
Juneau
19.0
22.7
26.7
32.1
38.9
45.0
48.1
47.3
42.9
37.2
27.2
22.6
34.1
AZ
Phoenix
41.2
44.7
48.8
55.3
63.9
72.9
81.0
79.2
72.8
60.8
48.9
41.8
59.3
AR
Little Rock
29.1
33.2
42.2
50.7
59.0
67.4
71.5
69.8
63.5
50.9
41.5
33.1
51.0
CA
Los Angeles
47.8
49.3
50.5
52.8
56.3
59.5
62.8
64.2
63.2
59.2
52.8
47.9
55.5
CA
Sacramento
37.7
41.4
43.2
45.5
50.3
55.3
58.1
58.0
55.7
50.4
43.4
37.8
48.1
CA
San Diego
48.9
50.7
52.8
55.6
59.1
61.9
65.7
67.3
65.6
60.9
53.9
48.8
57.6
CA
San Francisco
41.8
45.0
45.8
47.2
49.7
52.6
53.9
55.0
55.2
51.8
47.1
42.7
49.0
CO
Denver
16.1
20.2
25.8
34.5
43.6
52.4
58.6
56.9
47.6
36.4
25.4
17.4
36.2
CT
Hartford
15.8
18.6
28.1
37.5
47.6
56.9
62.2
60.4
51.8
40.7
32.8
21.3
39.5
DE
Wilmington
22.4
24.8
33.1
41.8
52.2
61.6
67.1
65.9
58.2
45.7
37.0
27.6
44.8
DC
Washington
26.8
29.1
37.7
46.4
56.6
66.5
71.4
70.0
62.5
50.3
41.1
31.7
49.2
FL
Jacksonville
40.5
43.3
49.2
54.9
62.1
69.1
71.9
71.8
69.0
59.3
50.2
43.4
57.1
FL
Miami
59.2
60.4
64.2
67.8
72.1
75.1
76.2
76.7
75.9
72.1
66.7
61.5
69.0
GA
Atlanta
31.5
34.5
42.5
50.2
58.7
66.2
69.5
69.0
63.5
51.9
42.8
35.0
51.3
HI
Honolulu
65.6
65.4
67.2
68.7
70.3
72.2
73.5
74.2
73.5
72.3
70.3
67.0
70.0
ID
Boise
21.6
27.5
31.9
36.7
43.9
52.1
57.7
56.8
48.2
39.0
31.1
22.5
39.1
IL
Chicago
12.9
17.2
28.5
38.6
47.7
57.5
62.6
61.6
53.9
42.2
31.6
19.1
39.5
IL
Peoria
13.2
17.7
29.8
40.8
50.9
60.7
65.4
63.1
55.2
43.1
32.5
19.3
41.0
IN
Indianapolis
17.2
20.9
31.9
41.5
51.7
61.0
65.2
62.8
55.6
43.5
34.1
23.2
42.4
IA
Des Moines
10.7
15.6
27.6
40.0
51.5
61.2
66.5
63.6
54.5
42.7
29.9
16.1
40.0
KS
Wichita
19.2
23.7
33.6
44.5
54.3
64.6
69.9
67.9
59.2
46.6
33.9
23.0
45.0
KY
Louisville
23.2
26.5
36.2
45.4
54.7
62.9
67.3
65.8
58.7
45.8
37.3
28.6
46.0
LA
New Orleans
41.8
44.4
51.6
58.4
65.2
70.8
73.1
72.8
69.5
58.7
51.0
44.8
58.5
ME
Portland
11.4
13.5
24.5
34.1
43.4
52.1
58.3
57.1
48.9
38.3
30.4
17.8
35.8
MD
Baltimore
23.4
25.9
34.1
42.5
52.6
61.8
66.8
65.7
58.4
45.9
37.1
28.2
45.2
MA
Boston
21.6
23.0
31.3
40.2
49.8
59.1
65.1
64.0
56.8
46.9
38.3
26.7
43.6
MI
Detroit
15.6
17.6
27.0
36.8
47.1
56.3
61.3
59.6
52.5
40.9
32.2
21.4
39.0
MI
Sault Ste. Marie
4.6
4.8
15.3
28.4
38.4
45.5
51.3
51.3
44.3
36.2
25.9
11.8
29.8
MN
Duluth
-2.2
2.8
15.7
28.9
39.6
48.5
55.1
53.3
44.5
35.1
21.5
4.9
29.0
MN
Minneapolis-St. Paul
2.8
9.2
22.7
36.2
47.6
57.6
63.1
60.3
50.3
38.8
25.2
10.2
35.3
MS
Jackson
32.7
35.7
44.1
51.9
60.0
67.1
70.5
69.7
63.7
50.3
42.3
36.1
52.0
MO
Kansas City
16.7
21.8
32.6
43.8
53.9
63.1
68.2
65.7
56.9
45.7
33.6
21.9
43.7
MO
St. Louis
20.8
25.1
35.5
46.4
56.0
65.7
70.4
67.9
60.5
48.3
37.7
26.0
46.7
MT
Great Falls
11.6
17.2
22.8
31.9
40.9
48.6
53.2
52.2
43.5
35.8
24.3
14.6
33.1
2.3 对数据集进行汇总
如今的实验涉及到的数据规模通常比较大。例如,为了了解某些行为习惯对健康的影响,1951 年,医学统计学家 R. Doll 和 A. B. Hill 向英国的所有医生发起了一项调查问卷,并且回收到了大约 40,000 份问卷。问卷的问题涉及年龄、饮食习惯和吸烟习惯。随后,Doll 和 Hill 对问卷回复者进行了为期 10 年的跟踪调查,并对其中的死亡人员的死因进行了监测。为了感知如此大量的数据,需要选择适当的方法对数据进行总结。在本节中,我们将介绍一些汇总数据的统计量,其中统计量是一个数值,数据集决定了其统计量的具体数值。
练习 2.4 1972 年,Hoel, D. G. 发表了一篇论文 A representation of mor- tality data by competing risks。在这篇论文中,Hoel 首先让一组 5 周大的小白鼠接受 300rad 的辐射剂量,然后把这些小白鼠分成两组:第一组置于无菌环境中,第二组则置于常规的实验室环境。随后,Hoel 观察并记录这些小白鼠的生存天数。以下的茎叶图(茎以百天为单位)记录了因胸腺淋巴瘤死亡的小白鼠的数据:第一张图是生活在无菌条件下的小白鼠,第二张图是生活在普通实验室条件下的小白鼠。