失效率函数
考虑一个正值连续随机变量 \(X\) ,我们将其解释为某个物品的寿命,其分布函数为 \(F\) ,密度函数为 \(f\) 。\(F\) 的 失效率函数 (hazard rate function ,有时也称为 故障率函数 failure rate function ) \(\lambda(t)\) 定义为:
\[
\lambda(t) = \frac{f(t)}{1 - F(t)}
\tag{14.1}\]
为了理解 \(\lambda(t)\) 的含义,假设该物品已经存活了 \(t\) 小时,我们想要知道它在接下来的 \(dt\) 时间内失效的概率。也就是说,考虑 \(P\{X \in (t, t + dt) | X > t\}\) 。注意到:
\[
\begin{align}
P\{X \in (t, t + dt) | X > t\} &= \frac{P\{X \in (t, t + dt), X > t\}}{P\{X > t\}} \\
&= \frac{P\{X \in (t, t + dt)\}}{P\{X > t\}} \\
&\approx \frac{f(t) dt}{1 - F(t)}
\end{align}
\]
也就是说,\(\lambda(t)\) 表示一个年龄为 \(t\) 的物品在下一时刻失效的 条件概率强度 (conditional probability intensity )。
假设现在的寿命分布是指数分布。那么,根据指数分布的无记忆性(memoryless property ),一个 \(t\) 岁的物品的剩余寿命分布与一个新物品的寿命分布相同。因此,\(\lambda(t)\) 应该是常数,验证如下:
\[
\begin{align}
\lambda(t) &= \frac{f(t)}{1 - F(t)} \\
&= \frac{\lambda e^{-\lambda t}}{e^{-\lambda t}} \\
&= \lambda
\end{align}
\]
因此,指数分布的失效率函数是常数。参数 \(\lambda\) 通常被称为该分布的 速率 (rate )。
我们现在证明失效率函数 \(\lambda(t), t \geq 0\) 唯一确定了分布 \(F\) 。为此,注意到根据定义:
\[
\begin{align}
\lambda(s) &= \frac{f(s)}{1 - F(s)} \\
&= \frac{\frac{d}{ds} F(s)}{1 - F(s)} \\
&= \frac{d}{ds} \{-\log[1 - F(s)]\}
\end{align}
\]
对该等式两边从 \(0\) 到 \(t\) 进行积分,得:
\[
\int_0^t \lambda(s) ds = -\log[1 - F(t)] + \log[1 - F(0)]
\]
由于 \(F(0) = 0\) ,上式变为:
\[
\int_0^t \lambda(s) ds = -\log[1 - F(t)]
\]
即:
\[
1 - F(t) = \exp\left\{-\int_0^t \lambda(s) ds\right\}
\tag{14.2}\]
因此,可以通过给出正连续随机变量的失效率函数来指定其分布函数。例如,如果一个随机变量具有线性失效率函数,即 \(\lambda(t) = a + bt\) ,那么其分布函数由下式给出:
\[
F(t) = 1 - e^{-(at + bt^2/2)}
\]
求导后可得其密度函数为:
\[
f(t) = (a + bt)e^{-(at + bt^2/2)}, \quad t \geq 0
\]
当 \(a = 0\) 时,上述分布被称为 瑞利密度函数 (Rayleigh density function )。
练习 14.1
答案 14.1 . \(\lambda_s(t)\) 表示 \(t\) 岁吸烟者的失效率,\(\lambda_n(t)\) 表示 \(t\) 岁不吸烟者的失效率,那么上述说法等同于 \(\lambda_s(t) = 2\lambda_n(t)\) 。
一个 \(A\) 岁的不吸烟者生存到 \(B\) 岁(\(A < B\) )的概率为:
\[
\begin{align}
P\{A \text{ 岁不吸烟者达到 } B \text{ 岁}\} &= P\{\text{不吸烟者的寿命} > B | \text{不吸烟者的寿命} > A\} \\
&= \frac{1 - F_{\text{non}}(B)}{1 - F_{\text{non}}(A)} \\
&= \frac{\exp\left\{-\int_0^B \lambda_n(t) dt\right\}}{\exp\left\{-\int_0^A \lambda_n(t) dt\right\}} \\
&= \exp\left\{-\int_A^B \lambda_n(t) dt\right\}
\end{align}
\]
而对于吸烟者,同理可得相应的概率为:
\[
\begin{align}
P\{A \text{ 岁吸烟者达到 } B \text{ 岁}\} &= \exp\left\{-\int_A^B \lambda_s(t) dt\right\} \\
&= \exp\left\{-2 \int_A^B \lambda_n(t) dt\right\} \\
&= \left[\exp\left\{-\int_A^B \lambda_n(t) dt\right\}\right]^2
\end{align}
\]
换句话说,对于两个同龄的人,一个是吸烟者,另一个是不吸烟者,吸烟者生存到任何给定年龄的概率是不吸烟者相应概率的 平方 (而不是一半)。例如,如果 \(\lambda_n(t) = 1/20, 50 \leq t \leq 60\) ,那么一个 50 岁的不吸烟者活到 60 岁的概率是 \(e^{-1/2} = .607\) ,而吸烟者相应的概率是 \(e^{-1} = .368\) 。
关于术语的说明
当我们说 \(X\) 具有失效率函数 \(\lambda(t)\) 时,更准确的意思是指 \(X\) 的分布函数具有失效率函数 \(\lambda(t)\) 。
寿命测试中的指数分布
同时测试——在第 \(r\) 次失效时停止
假设我们正在测试一些寿命服从均值为 \(\theta\) (未知)的指数分布的项目。我们将 \(n\) 个独立的项目同时进行测试,并在总共出现 \(r\) (\(r \leq n\) )次失效时停止实验。问题是利用观测到的数据来估计均值 \(\theta\) 。
观测到的数据如下:
\[
x_1 \leq x_2 \leq \dots \leq x_r, \quad i_1, i_2, \dots, i_r
\tag{14.3}\]
其中,\(x_j\) 表示第 \(j\) 次失效发生的时间,而 \(i_j\) 表示第 \(j\) 个失效的项目编号。也就是说,如果我们令 \(X_i\) (\(i=1, \dots, n\) )表示第 \(i\) 个组件的寿命,那么当以下条件满足时,观测数据如 方程式 14.3 所示:
\[
X_{i_1} = x_1, X_{i_2} = x_2, \dots, X_{i_r} = x_r
\]
且其余 \(n-r\) 个 \(X_j\) 均大于 \(x_r\) 。
由于 \(X_{i_j}\) 的概率密度函数为:
\[
f_{X_{i_j}}(x_j) = \frac{1}{\theta} e^{-x_j/\theta}, \quad j=1, \dots, r
\]
根据独立性,\(X_{i_j}\) (\(j=1, \dots, r\) )的联合概率密度为:
\[
f_{X_{i_1}, \dots, X_{i_r}}(x_1, \dots, x_r) = \prod_{j=1}^r \frac{1}{\theta} e^{-x_j/\theta}
\]
此外,根据独立性,其余 \(n-r\) 个 \(X\) 均大于 \(x_r\) 的概率为:
\[
P\{X_j > x_r \text{ 对于 } j \neq i_1, \dots, i_r\} = (e^{-x_r/\theta})^{n-r}
\]
因此,观测数据的 似然 (likelihood ) 函数 \(L(x_1, \dots, x_r, i_1, \dots, i_r)\) 在 \(x_1 \leq x_2 \leq \dots \leq x_r\) 时为:
\[
\begin{align}
L(x_1, \dots, x_r, i_1, \dots, i_r) &= f_{X_{i_1}, \dots, X_{i_r}}(x_1, \dots, x_r) P\{X_j > x_r, j \neq i_1, \dots, i_r\} \notag \\
&= \frac{1}{\theta} e^{-x_1/\theta} \dots \frac{1}{\theta} e^{-x_r/\theta} (e^{-x_r/\theta})^{n-r} \notag \\
&= \frac{1}{\theta^r} \exp \left\{ - \frac{\sum_{i=1}^r x_i + (n-r)x_r}{\theta} \right\}
\end{align}
\tag{14.4}\]
方程式 14.4 中的似然函数不仅指定了前 \(r\) 次失效发生的时间 \(x_1 \leq x_2 \leq \dots \leq x_r\) ,还指定了失效项目的顺序 \(i_1, i_2, \dots, i_r\) 。如果我们只关心前 \(r\) 次失效的时间,由于从 \(n\) 个项目中选择 \(r\) 个项目失效并排序共有 \(n(n-1)\dots(n-r+1) = n!/(n-r)!\) 种可能,因此联合密度函数在 \(x_1 \leq x_2 \leq \dots \leq x_r\) 时为:
\[
f(x_1, x_2, \dots, x_r) = \frac{n!}{(n-r)!} \frac{1}{\theta^r} \exp \left\{ - \frac{\sum_{i=1}^r x_i + (n-r)x_r}{\theta} \right\}
\]
为了获得 \(\theta\) 的 最大似然估计量 (maximum likelihood estimator ),我们对 方程式 14.4 两边取对数:
\[
\log L(x_1, \dots, x_r, i_1, \dots, i_r) = -r \log \theta - \frac{\sum_{i=1}^r x_i + (n-r)x_r}{\theta}
\]
求导得:
\[
\frac{\partial}{\partial \theta} \log L = -\frac{r}{\theta} + \frac{\sum_{i=1}^r x_i + (n-r)x_r}{\theta^2}
\]
令导数为 0 并求解,得到最大似然估计值 \(\hat{\theta}\) 为:
\[
\hat{\theta} = \frac{\sum_{i=1}^r x_i + (n-r)x_r}{r}
\]
如果我们令 \(X_{(i)}\) 表示第 \(i\) 次失效发生的时间(\(X_{(i)}\) 称为第 \(i\) 个 顺序统计量 (order statistic )),那么 \(\theta\) 的最大似然估计量为:
\[
\begin{align}
\hat{\theta} &= \frac{\sum_{i=1}^r X_{(i)} + (n-r)X_{(r)}}{r} \notag \\
&= \frac{\tau}{r}
\end{align}
\tag{14.5}\]
其中 \(\tau\) 定义为 方程式 14.5 中的分子,称为 总测试时间统计量 (total-time-on-test statistic )。我们这样称呼它是因为第 \(i\) 个失效的项目运行了时间 \(X_{(i)}\) ,而其他 \(n-r\) 个项目在整个测试期间(持续时间为 \(X_{(r)}\) )都在运行。因此,所有项目在测试中的时间总和等于 \(\tau\) 。
为了获得 \(\theta\) 的置信区间,我们需要确定 \(\tau\) 的分布。回想 \(X_{(i)}\) 是第 \(i\) 次失效的时间,我们将重写 \(\tau\) 的表达式。与其将每个项目在测试中的时间相加,不如计算每两次相邻失效之间产生的额外测试时间。令 \(Y_i\) (\(i=1, \dots, r\) )表示第 \(i-1\) 次和第 \(i\) 次失效之间产生的额外测试时间。到第一次失效 \(X_{(1)}\) 为止,所有 \(n\) 个项目都在运行,因此总测试时间为:
\[
Y_1 = n X_{(1)}
\]
在第一次和第二次失效之间,共有 \(n-1\) 个项目在运行,因此:
\[
Y_2 = (n-1)(X_{(2)} - X_{(1)})
\]
一般地,有:
\[
\begin{align*}
Y_1 &= n X_{(1)} \\
Y_2 &= (n-1)(X_{(2)} - X_{(1)}) \\
&\vdots \\
Y_j &= (n-j+1)(X_{(j)} - X_{(j-1)}) \\
&\vdots \\
Y_r &= (n-r+1)(X_{(r)} - X_{(r-1)})
\end{align*}
\]
且
\[
\tau = \sum_{j=1}^r Y_j
\]
这种表示方法的意义在于 \(Y_j\) 的分布很容易获得。由于第一次失效的时间 \(X_{(1)}\) 是 \(n\) 个独立指数寿命(率均为 \(1/\theta\) )的最小值,由 章节 5.6.1 \(n/\theta\) 的指数分布。也就是说,\(X_{(1)}\) 服从均值为 \(\theta/n\) 的指数分布,因此 \(n X_{(1)}\) 服从均值为 \(\theta\) 的指数分布。此外,在第一次失效发生的时刻,剩余的 \(n-1\) 个项目由于指数分布的无记忆性,就像新的一样,因此每个项目都有额外的寿命服从均值为 \(\theta\) 的指数分布;因此,直到其中一个失效的额外时间服从率为 \((n-1)/\theta\) 的指数分布。也就是说,独立于 \(X_{(1)}\) ,\(X_{(2)} - X_{(1)}\) 服从均值为 \(\theta/(n-1)\) 的指数分布,因此 \(Y_2 = (n-1)(X_{(2)} - X_{(1)})\) 服从均值为 \(\theta\) 的指数分布。事实上,继续这个论证可以得到以下结论:
\[
Y_1, \dots, Y_r \text{ 是独立的指数随机变量,每个的均值均为 } \theta
\tag{14.6}\]
由于独立同分布的指数随机变量之和服从伽马分布(推论 5.7.2),我们得到:
\[
\tau \sim \text{gamma}(r, 1/\theta)
\]
即 \(\tau\) 服从参数为 \(r\) 和 \(1/\theta\) 的伽马分布。等价地,回想参数为 \((r, 1/\theta)\) 的伽马随机变量等价于 \(\theta/2\) 乘以自由度为 \(2r\) 的卡方随机变量(见 章节 5.8.1
\[
\frac{2\tau}{\theta} \sim \chi^2_{2r}
\tag{14.7}\]
即 \(2\tau/\theta\) 服从自由度为 \(2r\) 的卡方分布。因此,
\[
P\{\chi^2_{1-\alpha/2, 2r} < 2\tau/\theta < \chi^2_{\alpha/2, 2r}\} = 1 - \alpha
\]
于是 \(\theta\) 的 \(100(1-\alpha)\%\) 置信区间为:
\[
\theta \in \left( \frac{2\tau}{\chi^2_{\alpha/2, 2r}}, \frac{2\tau}{\chi^2_{1-\alpha/2, 2r}} \right)
\tag{14.8}\]
单侧置信区间可以类似地获得。
练习 14.2
答案 14.2 .
\[
\chi^2_{.025, 30} = 46.97924, \quad \chi^2_{.975, 30} = 16.79077
\]
因此,使用 方程式 14.8 ,我们可以以 95% 的置信度断言:
\[
\theta \in (22.35, 62.17)
\]
在检验关于 \(\theta\) 的假设时,我们可以使用 方程式 14.8 来确定测试数据的 \(p\) 值。例如,假设我们对以下单侧检验感兴趣:
\[
H_0: \theta \geq \theta_0
\]
相对于备择假设
\[
H_1: \theta < \theta_0
\]
测试方法是首先计算测试统计量 \(2\tau/\theta_0\) 的值(记为 \(v\) ),然后计算当 \(H_0\) 为真时,自由度为 \(2r\) 的卡方随机变量小于或等于 \(v\) 的概率。这个概率就是 \(p\) 值,它代表了如果 \(H_0\) 为真,观测到像 \(2\tau/\theta_0\) 这么小(极大值)概率的可能性。如果显著性水平 \(\alpha\) 至少与该 \(p\) 值一样大,则应拒绝该假设。
练习 14.3
答案 14.3 . \(2\tau/\theta_0 = 3600/150 = 24\) ,因此 \(p\) 值为:
\[
p\text{-value} = P\{\chi^2_{40} \leq 24\} = \text{pchisq}(24, 40) = .02127977
\]
因此,应在 5% 的显著性水平下拒绝生产商的说法(实际上在任何大于或等于 .021 的显著性水平下都会拒绝)。
从 方程式 14.7 可以看出,估计量 \(\tau/r\) 的精度仅取决于 \(r\) 而非 \(n\) (投入测试的项目数)。\(n\) 的重要性在于通过选择足够大的 \(n\) ,我们可以确保测试很有可能持续时间较短。事实上,\(X_{(r)}\) (测试结束的时间)的矩很容易获得。由于(令 \(X_{(0)} \equiv 0\) ):
\[
X_{(j)} - X_{(j-1)} = \frac{Y_j}{n-j+1}, \quad j=1, \dots, r
\]
求和得到:
\[
X_{(r)} = \sum_{j=1}^r \frac{Y_j}{n-j+1}
\]
根据 方程式 14.6 ,\(X_{(r)}\) 是 \(r\) 个独立指数随机变量之和,这些变量的均值分别为 \(\theta/n, \theta/(n-1), \dots, \theta/(n-r+1)\) 。利用这一点,我们看到:
\[
E[X_{(r)}] = \sum_{j=1}^r \frac{\theta}{n-j+1} = \theta \sum_{j=n-r+1}^n \frac{1}{j}
\tag{14.9}\]
\[
\text{Var}(X_{(r)}) = \sum_{j=1}^r \left( \frac{\theta}{n-j+1} \right)^2 = \theta^2 \sum_{j=n-r+1}^n \frac{1}{j^2}
\]
其中第二个等式利用了指数随机变量的方差等于其均值平方的事实。当 \(n\) 较大时,我们可以按如下方式近似上述和:
\[
\begin{align*}
\sum_{j=n-r+1}^n \frac{1}{j} &\approx \int_{n-r+1}^n \frac{dx}{x} = \log \left( \frac{n}{n-r+1} \right) \\
\sum_{j=n-r+1}^n \frac{1}{j^2} &\approx \int_{n-r+1}^n \frac{dx}{x^2} = \frac{1}{n-r+1} - \frac{1}{n} = \frac{r-1}{n(n-r+1)}
\end{align*}
\]
因此,例如,如果在 练习 14.3 中真实的平均寿命为 120 小时,则测试长度的期望和方差大约为:
\[
\begin{align*}
E[X_{(20)}] &\approx 120 \log \left( \frac{100}{81} \right) = 25.29 \\
\text{Var}(X_{(20)}) &\approx (120)^2 \frac{19}{100(81)} = 33.78
\end{align*}
\]
序贯测试
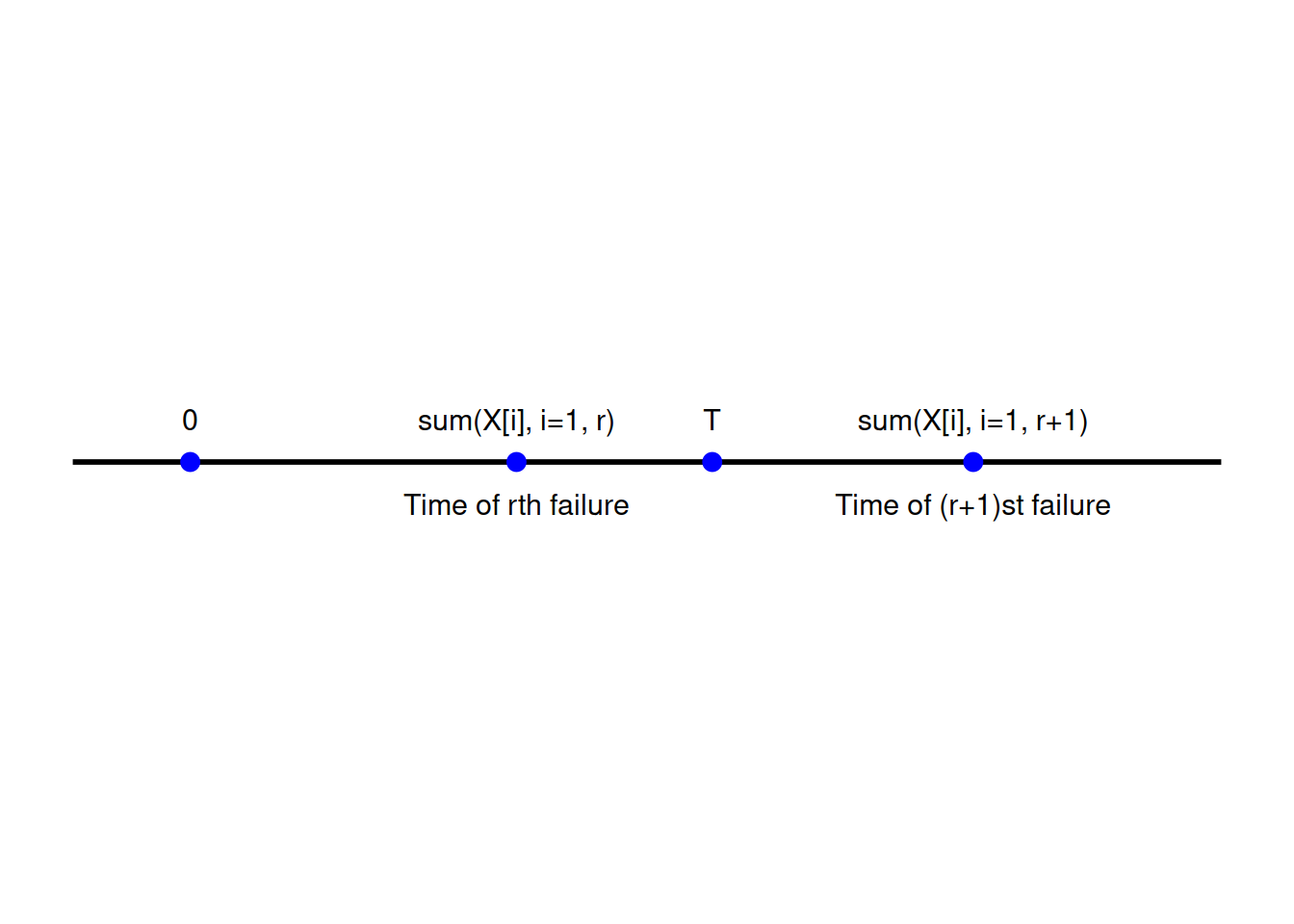
假设我们有无限量的项目,每个项目的寿命服从未知均值为 \(\theta\) 的指数分布,这些项目将按顺序进行测试,即第一个项目投入测试,失效后立即更换为第二个项目,依此类推。也就是说,一旦一个项目失效,它就会立即在寿命测试中被下一个项目替换。我们假设在某个固定时间 \(T\) 测试结束。
观测到的数据将包括: 数据:\(r, x_1, x_2, \dots, x_r\)
代码
library (ggplot2)# Define key time points <- data.frame (x = c (0 , 5 , 8 , 12 ),label = c ("0" , "sum(X[i], i=1, r)" , "T" , "sum(X[i], i=1, r+1)" ),text_label = c ("" , "Time of rth failure" , "" , "Time of (r+1)st failure" )ggplot (df, aes (x = x, y = 0 )) + # Main timeline geom_hline (yintercept = 0 , size = 1 , color = "black" ) + # Marks geom_point (size = 3 , color = "blue" ) + # Mathematical labels (above the line) geom_text (aes (label = label), vjust = - 1.5 , size = 4 ) + # English descriptive labels (below the line) geom_text (aes (label = text_label), vjust = 2.5 , size = 4 ) + # Scale and theme scale_x_continuous (limits = c (- 1 , 15 )) + scale_y_continuous (limits = c (- 0.5 , 0.5 )) + theme_void () + theme (plot.margin = unit (c (1 , 1 , 1 , 1 ), "cm" ))
其解释是到时间 \(T\) 为止共有 \(r\) 次失效,其中第 \(i\) 个测试项目运行了时间 \(x_i\) 。如果在时间 \(T\) 之前发生了 \(r\) 次失效,则观测数据如下:
\[
X_i = x_i, \quad i=1, \dots, r, \quad \sum_{i=1}^r x_i < T
\tag{14.10}\]
\[
X_{r+1} > T - \sum_{i=1}^r x_i
\]
其中 \(X_i\) 是第 \(i\) 个投入使用的组件的泛函寿命。这是因为,为了发生 \(r\) 次失效,第 \(r\) 次失效必须在时间 \(T\) 之前发生——即 \(\sum_{i=1}^r X_i < T\) ——且第 \((r+1)\) 个项目的泛函寿命必须超过 \(T - \sum_{i=1}^r X_i\) (见 图 14.1 )。
根据 方程式 14.10 ,我们得到数据 \(r, x_1, \dots, x_r\) 的似然函数如下:
\[
\begin{align*}
f(r, x_1, \dots, x_r | \theta) &= f_{X_1, \dots, X_r}(x_1, \dots, x_r) P\left\{ X_{r+1} > T - \sum_{i=1}^r x_i \right\}, \quad \sum_{i=1}^r x_i < T \\
&= \frac{1}{\theta^r} e^{-\sum_{i=1}^r x_i/\theta} e^{-(T - \sum_{i=1}^r x_i)/\theta} \\
&= \frac{1}{\theta^r} e^{-T/\theta}
\end{align*}
\]
因此,
\[
\log f(r, x_1, \dots, x_r | \theta) = -r \log \theta - \frac{T}{\theta}
\]
于是
\[
\frac{\partial}{\partial \theta} \log f(r, x_1, \dots, x_r | \theta) = -\frac{r}{\theta} + \frac{T}{\theta^2}
\]
令导数为 0 并求解,得到最大似然估计值为:
\[
\hat{\theta} = \frac{T}{r}
\]
由于 \(T\) 是所有项目的总测试时间,这再次表明,指数分布未知均值的最大似然估计值等于总测试时间除以这段时间内观测到的失效次数。
如果我们令 \(N(T)\) 表示到时间 \(T\) 为止的失效次数,那么 \(\theta\) 的最大似然估计量为 \(T/N(T)\) 。假设 \(N(T)\) 的观测值为 \(N(T)=r\) 。为了确定 \(\theta\) 的 \(100(1-\alpha)\%\) 置信区间估计值,我们首先要确定 \(\theta_L\) 和 \(\theta_U\) ,使得:
\[
P_{\theta_U}\{N(T) \geq r\} = \frac{\alpha}{2}, \quad P_{\theta_L}\{N(T) \leq r\} = \frac{\alpha}{2}
\]
其中 \(P_\theta(A)\) 表示在假设 \(\theta\) 是真实均值的情况下计算事件 \(A\) 的概率。\(\theta\) 的 \(100(1-\alpha)\%\) 置信区间估计值为:
\[
\theta \in (\theta_L, \theta_U)
\]
为了理解为什么不包含那些 \(\theta < \theta_L\) 或 \(\theta > \theta_U\) 的 \(\theta\) 值,请注意 \(P_\theta\{N(T) \geq r\}\) 随 \(\theta\) 递减,而 \(P_\theta\{N(T) \leq r\}\) 随 \(\theta\) 递增(为什么?)。因此, 如果 \(\theta < \theta_L\) ,那么 \(P_\theta\{N(T) \leq r\} < P_{\theta_L}\{N(T) \leq r\} = \frac{\alpha}{2}\) 如果 \(\theta > \theta_U\) ,那么 \(P_\theta\{N(T) \geq r\} < P_{\theta_U}\{N(T) \geq r\} = \frac{\alpha}{2}\)
接下来需要确定 \(\theta_L\) 和 \(\theta_U\) 。为此,首先注意事件 \(N(T) \geq r\) 等价于第 \(r\) 次失效在时间 \(T\) 之前或之时发生的陈述。也就是说,
\[
N(T) \geq r \iff X_1 + \dots + X_r \leq T
\]
因此
\[
\begin{align*}
P_\theta\{N(T) \geq r\} &= P_\theta\{X_1 + \dots + X_r \leq T\} \\
&= P\{\text{gamma}(r, 1/\theta) \leq T\} \\
&= P\left\{ \frac{\theta}{2} \chi^2_{2r} \leq T \right\} \\
&= P\{\chi^2_{2r} \leq 2T/\theta\}
\end{align*}
\]
因此,在 \(\theta = \theta_U\) 处评估上述式子,并利用 \(P\{\chi^2_{2r} \leq \chi^2_{1-\alpha/2, 2r}\} = \alpha/2\) ,我们得到:
\[
\frac{\alpha}{2} = P\left\{ \chi^2_{2r} \leq \frac{2T}{\theta_U} \right\}
\]
并且
\[
\frac{2T}{\theta_U} = \chi^2_{1-\alpha/2, 2r}
\]
或
\[
\theta_U = 2T/\chi^2_{1-\alpha/2, 2r}
\]
类似地,我们可以证明
\[
\theta_L = 2T/\chi^2_{\alpha/2, 2r}
\]
因此 \(\theta\) 的 \(100(1-\alpha)\%\) 置信区间估计值为:
\[
\theta \in (2T/\chi^2_{\alpha/2, 2r}, 2T/\chi^2_{1-\alpha/2, 2r})
\]
例子 14.1 \(T = 500\) 小时内产生了 10 次失效,那么 \(\theta\) 的最大似然估计值为 \(500/10 = 50\) 小时。 \(\theta\) 的 95% 置信区间估计值为:
\[
0 \in (1000/\chi^2_{.025, 20}, 1000/\chi^2_{.975, 20})
\]
R 给出:
\[
\chi^2_{.025, 20} = 34.16961, \quad \chi^2_{.975, 20} = 9.590777
\]
所以,以 95% 的置信度,
\[
\theta \in (29.27, 103.52)
\]
如果我们想检验假设
\[
H_0: \theta = \theta_0
\]
相对于备择假设
\[
H_1: \theta \neq \theta_0
\]
那么我们首先要确定 \(N(T)\) 的值。如果 \(N(T) = r\) ,那么在满足以下任一条件时拒绝该假设:
\[
P_{\theta_0}\{N(T) \leq r\} \leq \frac{\alpha}{2} \quad \text{或} \quad P_{\theta_0}\{N(T) \geq r\} \leq \frac{\alpha}{2}
\]
换句话说,如果在由下式给出的 \(p\) 值小于或等于显著性水平 \(\alpha\) 时,将拒绝 \(H_0\) :
\[
\begin{align*}
p\text{-value} &= 2 \min(P_{\theta_0}\{N(T) \geq r\}, P_{\theta_0}\{N(T) \leq r\}) \\
&= 2 \min(P_{\theta_0}\{N(T) \geq r\}, 1 - P_{\theta_0}\{N(T) \geq r + 1\}) \\
&= 2 \min\left( P\left\{ \chi^2_{2r} \leq \frac{2T}{\theta_0} \right\}, 1 - P\left\{ \chi^2_{2(r+1)} \leq \frac{2T}{\theta_0} \right\} \right)
\end{align*}
\]
单侧检验的 \(p\) 值可以类似地获得。
练习 14.4
答案 14.4 .
\[
H_0: \theta \geq 25 \quad \text{相对于} \quad H_1: \theta < 25
\]
确定 \(p\) 值的相关概率是:如果平均寿命为 25,发生至少 30 次失效的概率。即:
\[
\begin{align*}
p\text{-value} &= P_{25}\{N(600) \geq 30\} \\
&= P\{\chi^2_{60} \leq 1200/25\} \\
&= .1321236 \quad (\text{来自 R})
\end{align*}
\]
因此,当显著性水平为 .10 时,应接受 \(H_0\) 。
同时测试——在固定时间停止
再次假设我们正在测试寿命服从独立同分布、均值均为 \(\theta\) (未知)的指数随机变量的项目。如 章节 14.3.1 \(n\) 个项目同时投入测试,但现在我们假设测试要在某个固定时间 \(T\) 停止,或者在所有 \(n\) 个项目全部失效时停止——以先到者为准。问题是利用观测数据来估计 \(\theta\) 。
观测数据如下: 数据:\(i_1, i_2, \dots, i_r, \quad x_1, x_2, \dots, x_r\) 其解释是当编号为 \(i_1, \dots, i_r\) 的 \(r\) 个项目被观测到分别在时间 \(x_1, \dots, x_r\) 失效,而其余 \(n-r\) 个项目到时间 \(T\) 尚未失效时,得到上述结果。
由于项目在时间 \(T\) 之前尚未失效当且仅当其寿命大于 \(T\) ,我们看到上述数据的似然函数为:
\[
\begin{align*}
f(i_1, \dots, i_r, x_1, \dots, x_r) &= f_{X_{i_1}, \dots, X_{i_r}}(x_1, \dots, x_r) P\{X_j > T, j \neq i_1, \dots, i_r\} \\
&= \frac{1}{\theta} e^{-x_1/\theta} \dots \frac{1}{\theta} e^{-x_r/\theta} (e^{-T/\theta})^{n-r} \\
&= \frac{1}{\theta^r} \exp \left\{ - \frac{\sum_{i=1}^r x_i + (n-r)T}{\theta} \right\}
\end{align*}
\]
为了获得最大似然估计值,取对数得到:
\[
\log f(i_1, \dots, i_r, x_1, \dots, x_r) = -r \log \theta - \frac{\sum_{i=1}^r x_i + (n-r)T}{\theta}
\]
于是,
\[
\frac{\partial}{\partial \theta} \log f(i_1, \dots, i_r, x_1, \dots, x_r) = -\frac{r}{\theta} + \frac{\sum_{i=1}^r x_i + (n-r)T}{\theta^2}
\]
令导数为 0 并求解,得到最大似然估计值 \(\hat{\theta}\) 为:
\[
\hat{\theta} = \frac{\sum_{i=1}^r x_i + (n-r)T}{r}
\]
因此,如果我们令 \(R\) 表示到时间 \(T\) 为止失效的项目数,并令 \(X_{(i)}\) 为第 \(i\) 个最小的失效时间,\(i=1, \dots, R\) ,那么 \(\theta\) 的最大似然估计量为:
\[
\hat{\theta} = \frac{\sum_{i=1}^R X_{(i)} + (n-R)T}{R}
\]
令 \(\tau\) 表示所有项目在寿命测试中的时间总和。那么,因为 \(R\) 个失效的项目在测试中的时间为 \(X_{(1)}, \dots, X_{(R)}\) ,而 \(n-R\) 个未失效的项目在测试中的时间均为 \(T\) ,所以:
\[
\tau = \sum_{i=1}^R X_{(i)} + (n-R)T
\]
从而我们可以将最大似然估计量写为:
\[
\hat{\theta} = \frac{\tau}{R}
\]
换言之,平均寿命的最大似然估计量(如 章节 14.3.1 章节 14.3.2
正如读者可能已经猜到的那样,事实证明,对于指数分布的所有可能寿命测试方案,未知均值 \(\theta\) 的最大似然估计量将始终等于总测试时间除以观测到的失效次数。为了看清这一点,考虑任何测试情况,并假设数据结果是:\(r\) 个项目在分别测试了时间 \(x_1, \dots, x_r\) 后被观测到失效,而 \(s\) 个项目在测试结束时尚未失效——此时它们分别测试了时间 \(y_1, \dots, y_s\) 。这一结果的似然函数将是:
\[
\begin{align}
\text{likelihood} &= K \frac{1}{\theta} e^{-x_1/\theta} \dots \frac{1}{\theta} e^{-x_r/\theta} e^{-y_1/\theta} \dots e^{-y_s/\theta} \notag \\
&= \frac{K}{\theta^r} \exp \left\{ - \frac{\sum_{i=1}^r x_i + \sum_{i=1}^s y_i}{\theta} \right\}
\end{align}
\tag{14.11}\]
其中 \(K\) 是测试方案和数据的函数,不取决于 \(\theta\) 。(例如,\(K\) 可能与测试程序有关,其中停止测试的决定可能取决于观测数据,或者是随机的。)根据前述内容,\(\theta\) 的最大似然估计值将是:
\[
\hat{\theta} = \frac{\sum_{i=1}^r x_i + \sum_{i=1}^s y_i}{r}
\tag{14.12}\]
但是 \(\sum_{i=1}^r x_i + \sum_{i=1}^s y_i\) 正是总测试时间统计量,因此 \(\theta\) 的最大似然估计量确实是总测试时间除以这段时间的失效次数。
对于本节中描述的寿命测试方案,\(\tau/R\) 的分布相当复杂,因此我们将无法轻易推导 \(\theta\) 的置信区间估计量。事实上,我们不会进一步探讨这个问题,而是考虑估计 \(\theta\) 的贝叶斯方法。
贝叶斯方法
假设将具有独立同分布指数寿命、未知均值为 \(\theta\) 的项目投入寿命测试。那么,正如 章节 14.3.3
\[
f(\text{data}|\theta) = \frac{K}{\theta^r} e^{-t/\theta}
\]
其中 \(t\) 是总测试时间——即所用所有项目的测试时间之和——而 \(r\) 是给定数据的观测失效次数。
令 \(\lambda = 1/\theta\) 表示指数分布的率。在贝叶斯方法中,使用率 \(\lambda\) 而不是其倒数更方便。根据前述内容我们看到:
\[
f(\text{data}|\lambda) = K \lambda^r e^{-\lambda t}
\]
如果我们假设在测试之前,\(\lambda\) 按照先验密度 \(g(\lambda)\) 分布,那么给定观测数据的 \(\lambda\) 后验密度如下:
\[
\begin{align}
f(\lambda|\text{data}) &= \frac{f(\text{data}|\lambda)g(\lambda)}{\int f(\text{data}|\lambda)g(\lambda) d\lambda} \notag \\
&= \frac{\lambda^r e^{-\lambda t} g(\lambda)}{\int \lambda^r e^{-\lambda t} g(\lambda) d\lambda}
\end{align}
\tag{14.13}\]
当 \(g\) 是参数为(比如)\((b, a)\) 的伽马密度函数时,上述后验密度处理起来特别方便——也就是说,当
\[
g(\lambda) = \frac{a e^{-a\lambda}(a\lambda)^{b-1}}{\Gamma(b)}, \quad \lambda > 0
\]
对于某些非负常数 \(a\) 和 \(b\) 。事实上,对于这一 \(g\) 的选择,我们根据 方程式 14.13 得到:
\[
\begin{align*}
f(\lambda|\text{data}) &= C e^{-(a+t)\lambda} \lambda^{r+b-1} \\
&= K e^{-(a+t)\lambda} [(a+t)\lambda]^{b+r-1}
\end{align*}
\]
其中 \(C\) 和 \(K\) 不取决于 \(\lambda\) 。因为我们将前述内容识别为参数为 \((b+r, a+t)\) 的伽马密度,所以我们可以将其改写为:
\[
f(\lambda|\text{data}) = \frac{(a+t) e^{-(a+t)\lambda} [(a+t)\lambda]^{b+r-1}}{\Gamma(b+r)}, \quad \lambda > 0
\]
换言之,如果 \(\lambda\) 的先验分布是参数为 \((b, a)\) 的伽马分布,那么无论测试方案如何,给定数据的 \(\lambda\) (后验)条件分布是参数为 \((b+R, a+\tau)\) 的伽马分布,其中 \(\tau\) 和 \(R\) 分别代表总测试时间统计量和观测失效次数。由于参数为 \((b, a)\) 的伽马随机变量的均值等于 \(b/a\) (见 章节 5.7 \(\lambda\) 的贝叶斯估计量 \(E[\lambda|\text{data}]\) 为:
\[
E[\lambda|\text{data}] = \frac{b+R}{a+\tau}
\]
练习 14.5 \(\lambda\) 的项目在不同时间投入寿命测试。当测试结束时,有 10 次观测到的失效——它们的寿命(以小时计)为 5, 7, 6.2, 8.1, 7.9, 15, 18, 3.9, 4.6, 5.8。未失效的 10 个项目在测试终止时,已在测试中经历的时间(以小时计)分别为 3, 3.2, 4.1, 1.8, 1.6, 2.7, 1.2, 5.4, 10.3, 1.5。如果测试前认为 \(\lambda\) 可以被视为参数为 (2, 20) 的伽马随机变量,那么 \(\lambda\) 的贝叶斯估计值是多少?
答案 14.5 .
\[
\tau = 116.1, \quad R = 10
\]
由此得 \(\lambda\) 的贝叶斯估计值为:
\[
E[\lambda|\text{data}] = \frac{12}{136.1} = .088
\]
正如我们所见,为指数分布的率选择伽马先验分布使得所得计算相当简单。虽然从应用的角度来看,这并不是一个充分的理由,但通常会做出这样的选择,理由之一是固定伽马先验分布的两个参数所提供的灵活性通常能够使人合理地接近其真实的先验感受。
双样本问题
某公司建立了两个独立的工厂来生产真空管。公司假设工厂 I 生产的真空管寿命服从均值为 \(\theta_1\) 的指数分布,而工厂 II 生产的真空管寿命服从均值为 \(\theta_2\) 的指数分布。为了检验这两个工厂是否存在差异(至少在它们生产的真空管寿命方面),公司从工厂 I 抽取了 \(n\) 个真空管,从工厂 II 抽取了 \(m\) 个真空管,并测量了它们的寿命。那么,他们如何确定这两个工厂生产的真空管是否确实相同呢?
若令 \(X_1, \dots, X_n\) 表示工厂 I 生产的 \(n\) 个真空管的寿命,并令 \(Y_1, \dots, Y_m\) 表示工厂 II 生产的 \(m\) 个真空管的寿命。当 \(X_i\) (\(i = 1, \dots, n\) ) 是来自均值为 \(\theta_1\) 的指数分布的随机样本,且 \(Y_i\) (\(i = 1, \dots, m\) ) 是来自均值为 \(\theta_2\) 的指数分布的随机样本时,问题就转化为检验假设 \(\theta_1 = \theta_2\) 。此外,假设这两个样本是相互独立的。
为了开发关于 \(\theta_1 = \theta_2\) 的检验方法,我们首先注意到 \(\sum_{i=1}^n X_i\) 和 \(\sum_{i=1}^m Y_i\) (作为独立同分布指数随机变量之和)是独立的 伽马 (gamma ) 随机变量,其参数分别为 \((n, 1/\theta_1)\) 和 \((m, 1/\theta_2)\) 。因此,根据伽马分布与卡方分布的等价性可知: \[
\frac{2}{\theta_1} \sum_{i=1}^n X_i \sim \chi_{2n}^2
\] \[
\frac{2}{\theta_2} \sum_{i=1}^m Y_i \sim \chi_{2m}^2
\]
由 \(F\) -分布F-distribution ) 的定义可以得出: \[
\frac{\frac{2}{2n\theta_1} \sum_{i=1}^n X_i}{\frac{2}{2m\theta_2} \sum_{i=1}^m Y_i} \sim F_{2n,2m}
\tag{14.14}\]
也就是说,如果 \(\bar{X}\) 和 \(\bar{Y}\) 分别是两个样本的均值,那么 \(\frac{\theta_2 \bar{X}}{\theta_1 \bar{Y}}\) 服从自由度为 \(2n\) 和 \(2m\) 的 \(F\) -分布。
因此,当假设 \(\theta_1 = \theta_2\) 成立时,\(\bar{X}/\bar{Y}\) 服从自由度为 \(2n\) 和 \(2m\) 的 \(F\) -分布。这启发了如下关于 \(\theta_1 = \theta_2\) 的检验方法:
检验: \(H_0: \theta_1 = \theta_2\) 对抗备择假设 \(H_1: \theta_1 \neq \theta_2\)
步骤 1: 选择显著性水平 \(\alpha\) 。
步骤 2: 确定检验统计量 \(\bar{X}/\bar{Y}\) 的值 —— 设其值为 \(v\) 。
步骤 3: 计算 \(P\{F \leq v\}\) ,其中 \(F \sim F_{2n,2m}\) 。如果该概率小于 \(\alpha/2\) (这发生在 \(\bar{X}\) 显著小于 \(\bar{Y}\) 时),或者大于 \(1 - \alpha/2\) (这发生在 \(\bar{X}\) 显著大于 \(\bar{Y}\) 时),则拒绝原假设。
换句话说,检验数据的 \(p\) -值p-value ) 由下式给出: \[
p\text{-值} = 2 \min(P\{F \leq v\}, 1 - P\{F \leq v\})
\]
练习 14.6
答案 14.6 . \(\bar{X}/\bar{Y}\) 的值为 \(42/34 = 1.2353\) 。为了计算自由度为 20 和 30 的 \(F\) 随机变量小于该值的概率,我们使用 R 语言:
pf (1.2353 , 20 , 30 )# [1] 0.6553309 由于 \(p\) -值等于 \(2(1 - 0.6553) = 0.6894\) ,我们不能拒绝 \(H_0\) 。