12 LangChain Retrieval
在 章节 7 中,我们介绍了基于检索增强的生成式技术,这一章,我们重点介绍如何使用 LangChain 实现 RAG。
无论是简单的 RAG 应用,还是复杂的 RGA 应用,LangChain 都为我们提供了相应的构建能力。在 LangChain 中,RAG 的整个过程涉及到如 图 12.1 的模块和步骤:

12.1 Document loaders
LangChain 提供了100多种不同的文档加载器,并与该领域的其他主要供应商(如 AirByte、Unstructured)进行了集成,从而可以从任何地方(私有 s3 存储、网站)加载任何类型的文档(HTML、PDF、代码)。
文档加载器提供了一个 load() 方法来从指定的加载源加载文档数据。文档加载器还提供了一个 lazy_load() 方法来实现现“延迟加载”,以避免一次将太多的数据加载到内存之中。
列表 12.1: 加载远程网页
from langchain.document_loaders.recursive_url_loader import RecursiveUrlLoader
URL_ROOT = "https://wangwei1237.github.io/"
loader = RecursiveUrlLoader(url=URL, max_depth=2)
docs = loader.load()
print(len(docs))
URLS = []
for doc in docs:
url = doc.metadata["source"]
title = doc.metadata["title"]
print(url, "->", title)RecursiveUrlLoader() 对中文的抓取看起来不是非常友好,中文内容显示成了乱码。可以使用 列表 12.2 所示的方法来解决中文乱码的问题,不过这种方式的缺点是需要 load() 两次。更好的方式后续再思考。
列表 12.2: 解决中文乱码的方法
from langchain.document_loaders import WebBaseLoader
from langchain.document_loaders.recursive_url_loader import RecursiveUrlLoader
URL_ROOT = "https://wangwei1237.github.io/"
loader = RecursiveUrlLoader(url=URL_ROOT, max_depth=2)
docs = loader.load()
print(len(docs))
URLS = []
for doc in docs:
url = doc.metadata["source"]
URLS.append(url)
loader = WebBaseLoader(URLS)
docs = loader.load()
print(len(docs))
for doc in docs:
url = doc.metadata["source"]
title = doc.metadata["title"]
print(url, "->", title)12.2 Document transformers
检索的一个关键部分是只获取文档的相关部分而非获取全部文档。为了为最终的检索提供最好的文档,我们需要对文档进行很多的转换,这里的主要方法之一是将一个大文档进行拆分。LangChain 提供了多种不同的拆分算法,并且还针对特定文档类型(代码、标记等)的拆分提供对应的优化逻辑。
文档加载后,我们通常会对文档进行一系列的转换,以更好地适应我们的应用程序。最简单的文档转换的场景就是文档拆分成,以便可以满足模型的上下文窗口(不同模型的每次交互的最大 token 数可能不同)。
尽管文档拆分听起来很简单,但实际应用中却有很多潜在的复杂性。理想情况下,我们希望将语义相关的文本片段放在一起。“语义相关”的含义会取决于文本的类型,例如:
- 对于代码文件而言,我们需要将一个函数置于一个完整的拆分块中;
- 普通的文本而言,可能需要将一个段落置于一个完整的拆分块中;
- ……
我们利用 RecursiveCharacterTextSplitter 对 列表 12.2 的文档进行拆分。
列表 12.3: 使用 RecursiveCharacterTextSplitter 拆分文档
# ...
# ...
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
for doc in docs:
url = doc.metadata["source"]
title = doc.metadata["title"]
print(url, "-->", title)
texts = text_splitter.create_documents([doc.page_content])
print(texts)LangChain 也可以对不同的编程语言进行拆分,例如 cpp,go,markdown,……,具体支持的语言可以参见 列表 12.4。
列表 12.4: LangChain 支持拆分的语言类型
from langchain.text_splitter import Language
[e.value for e in Language]
#['cpp',
# 'go',
# 'java',
# 'js',
# 'php',
# 'proto',
# 'python',
# 'rst',
# 'ruby',
# 'rust',
# 'scala',
# 'swift',
# 'markdown',
# 'latex',
# 'html',
# 'sol']12.3 Text embedding models
检索的另一个关键部分是为文档创建其向量(embedding)表示。Embedding 捕获文本的语义信息,使我们能够快速、高效地查找其他相似的文本片段。LangChain 集成了 25 种不同的 embedding 供应商和方法,我们可以根据我们的具体需求从中进行选择。LangChain 还提供了一个标准接口,允许我们可以便捷的在不同的 embedding 之间进行交换。
在 LangChain 中,Embeddings 类是用于文本向量模型的接口。目前,有很多的向量模型供应商,例如:OpenAI,Cohere,Hugging Face,……Embeddings 类的目的就是为所有这些向量模型提供统一的、标准的接口。
Embeddings 类可以为一段文本创建对应的向量表示,从而允许我们可以在向量空间中去考虑文本。在向量空间中,我们还可以执行语义搜索,从而允许我们在向量空间中检索最相似的文本片段。
因为不同的向量模型供应商对文档和查询采用了不同的向量方法,Embeddings 提供了两个方法:
embed_documents():用于文档向量化embed_query():用于查询向量化
列表 12.5: 使用文心大模型的 Embedding-V1 查询向量化
from langchain.embeddings import QianfanEmbeddingsEndpoint
embeddings = QianfanEmbeddingsEndpoint()
query_result = embeddings.embed_query("你是谁?")
print(query_result)
print(len(query_result))
# [0.02949424833059311, -0.054236963391304016, -0.01735987327992916,
# 0.06794580817222595, -0.00020318820315878838, 0.04264984279870987,
# -0.0661700889468193, ……
# ……]
#
# 384列表 12.6: 使用文心大模型的 Embedding-V1 文档向量化
from langchain.embeddings import QianfanEmbeddingsEndpoint
embeddings = QianfanEmbeddingsEndpoint()
docs_result = embeddings.embed_documents([
"你谁谁?",
"我是百度的智能助手,小度"
])
print(len(docs_result), ":" , len(docs_result[0]))
# 2 : 384LangChain 在 0.0.300 版本之后才支持 QianfanEmbeddingsEndpoint,并且 QianfanEmbeddingsEndpoint 还依赖 qianfan python 库的支持。
因此,在使用 QianfanEmbeddingsEndpoint 之前,需要:
- 升级 LangChain 的版本:
pip install -U langchain。 - 安装
qianfan库:pip install qianfan。
12.4 Vector stores
为文档创建 embedding 之后,需要对其进行存储并实现对这些 embedding 的有效搜索,此时我们需要向量数据库的支持。LangChain 集成了 50 多种不同的向量数据库,还提供了一个标准接口,允许我们轻松的在不同的向量存储之间进行切换。
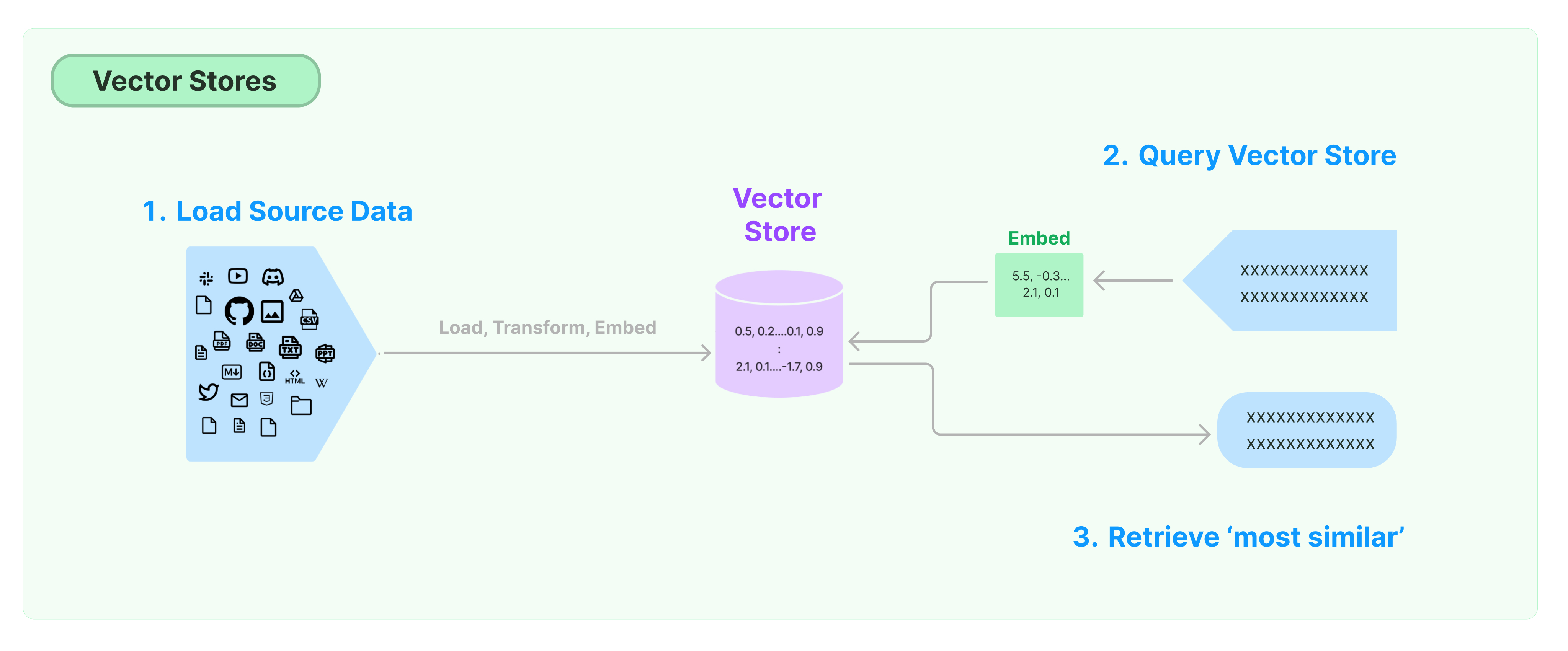
这里,我们使用 Milvus 向量数据库来进行相关的演示。Milvus 安装和使用方式可以参见:附录 C。
利用 Milvus 对 列表 12.6 进行优化:
列表 12.7: 使用 Milvus 存储千帆 Embedding-V1 的结果
from langchain.document_loaders import WebBaseLoader
from langchain.embeddings import QianfanEmbeddingsEndpoint
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Milvus
url = 'https://wangwei1237.github.io/2023/02/13/duzhiliao/'
loader = WebBaseLoader([url])
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 200,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
texts = text_splitter.create_documents([docs[0].page_content])
vector_db = Milvus.from_documents(
texts,
QianfanEmbeddingsEndpoint(),
connection_args ={"host": "127.0.0.1", "port": "8081"},
)
query = "什么是度知了?"
docs = vector_db.similarity_search(query)
print(docs)列表 12.7 的运行结果中,之所以会有两条重复的结果,是因为在执行文档向量化的时候,执行了两遍。在初始化 Milvus 实例时,如果只是查询操作,可以使用如下的方式:
列表 12.8: Milvus 实例初始化
vector_db = Milvus.from_documents(
[],
QianfanEmbeddingsEndpoint(),
connection_args ={"host": "127.0.0.1", "port": "8081"},
)Milvus.from_documents 会创建一个名为 LangChainCollection 的 Collection。可以使用 milvus_cli 工具来查看该 Collection 的信息,也可以使用 Milvus 提供的 http 端口来查看相关信息:
http://127.0.0.1:8081/v1/vector/collections/describe?collectionName=LangChainCollection为了方便使用,可以使用 collection_name 参数以实现将不同的专有数据源存储在不同的 Collection。
vector_db = Milvus.from_documents(
texts,
QianfanEmbeddingsEndpoint(),
connection_args={"host": "127.0.0.1", "port": "8081"},
1 collection_name="test",
)- 1
- 设置数据存储的 Collection,类似于在关系数据库中,将数据存储在不同的表中。
使用千帆进行 Embedding 时,每次 Embedding 的 token 是有长度限制的,目前的最大限制是 384 个 token。因此,我们在使用 RecursiveCharacterTextSplitter 进行文档拆分的时候要特别注意拆分后文档的长度。
qianfan.errors.APIError: api return error,
code: 336003,
msg: embeddings max tokens per batch size is 384在使用时,为了方便,我们可以把 embedding 和 query 拆分为两个部分:
- 先将数据源进行向量化,然后存储到 Milvus 中
- 检索的时候,直接从 Milvus 中检索相关信息
对 列表 12.6 的代码进行优化:
列表 12.9: 文档向量化后存入 Milvus
#encoding: utf-8
"""
@discribe: example for milvus embedding
@author: wangwei1237@gmail.com
"""
from langchain.document_loaders import WebBaseLoader
from langchain.document_loaders.recursive_url_loader import RecursiveUrlLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import WebBaseLoader
from langchain.embeddings import QianfanEmbeddingsEndpoint
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Milvus
import time
URL_ROOT = "https://wangwei1237.github.io/2023/02/13/duzhiliao/"
loader = RecursiveUrlLoader(url=URL_ROOT, max_depth=2)
docs = loader.load()
URLS = []
for doc in docs:
url = doc.metadata["source"]
URLS.append(url)
print("URLS length: ", len(URLS))
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 200,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
for url in URLS:
print('-------------', url, '----------------')
loader = WebBaseLoader([url])
doc = loader.load()
texts = text_splitter.split_documents(doc)
vector_db = Milvus.from_documents(
texts,
QianfanEmbeddingsEndpoint(),
connection_args ={"host": "127.0.0.1", "port": "8081"},
)
print(" . insert ", len(texts), " texts embeddings successful")
time.sleep(5)检索相似内容的代码可以简化为:
列表 12.10: 内容检索
#encoding: utf-8
"""
@discribe: example for milvus embedding query
@author: wangwei1237@gmail.com
"""
from langchain.embeddings import QianfanEmbeddingsEndpoint
from langchain.vectorstores import Milvus
vector_db = Milvus.from_documents(
[],
QianfanEmbeddingsEndpoint(),
connection_args ={"host": "127.0.0.1", "port": "8081"},
)
query = "什么是 RD曲线?"
docs = vector_db.similarity_search(query)
print(docs)
因为千帆向量化的 API 有 QPS 限制,因此,在使用千帆进行 embedding 时尽量控制一下 QPS。
12.5 Retrivers
检索是 LangChain 花费精力最大的环节,LangChain 提供了许多不同的检索算法,LangChain 不但支持简单的语义检索,而且还增加了很多算法以提高语义检索的性能。
一旦我们准备好了相关的数据,并且将这些数据存储到向量数据库(例如 Milvus),我们就可以配置一个 chain,并在 提示词 中包含这些相关数据,以便 LLM 在回答我们的问题时可以利用这些数据作为参考。
对于参考外部数据源的 QA 而言,LangChain 提供了 4 种 chain:stuff,map_reduce,refine,map_rerank。stuff chain 把文档作为整体包含到 提示词 中,这只适用于小型文档。由于大多数 LLM 对 提示次 可以包含的 token 最大数量存在限制,因此建议使用其他三种类型的 chain。对于非 stuff chain,LangChain 将输入文档分割成更小的部分,并以不同的方式将它们提供给 LLM。这 4 种 chain 的具体信息和区别可以参见:docs/modules/chains/document。
我们利用 QAWithSourcesChain 对 列表 12.10 进行优化,以实现一个完整的利用外部数据源的 Retrival Augment Generation(需要配合 列表 12.9)。
列表 12.11: 基于 LangChain 和 Milvus 的 RAG
#encoding: utf-8
"""
@discribe: example for RAG
@author: wangwei1237@gmail.com
"""
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.chat_models import ErnieBotChat
from langchain.embeddings import QianfanEmbeddingsEndpoint
from langchain.vectorstores import Milvus
llm = ErnieBotChat()
chain = load_qa_with_sources_chain(llm=llm, chain_type="refine", return_intermediate_steps=True)
query = "什么是度知了?"
vector_db = Milvus.from_documents(
[],
QianfanEmbeddingsEndpoint(),
connection_args ={"host": "127.0.0.1", "port": "8081"},
)
docs = vector_db.similarity_search(query)
print(len(docs))
res = chain({"input_documents": docs, "question": query}, return_only_outputs=True)
print(res)
列表 12.11 的运行结果如下,结果包括 intermediate_steps 和 output_text:
intermediate_steps表示搜索过程中所指的文档output_text表示是问题的最终答案
4
{'intermediate_steps':
[
'根据提供的上下文信息,回答问题:\n\n「度知了」是一个在线问答平台,使用指南是由作者严丽编写的。该平台供了一个问答系统,用户可以在其中提出问题和获取答案。「度知了」的目的是帮助用户更好地理解和掌握知识,并提供了一个方便的途径来获取所需的信息。',
'根据提供的上下文信息,「度知了」是一个在线问答平台,使用指南是由作者严丽编写的。该平台提供了一个问答系统,用户可以在其中提出问题和获取答案。「度知了」的目的是帮助用户更好地理解和掌握知识,并提供了一个方便的途径来获取所需的信息。度知了基于ITU标准,依托自研的10+项专利技术,在不断实践的基础之上而形成的一款支持多端(PC,Android,iOS)评测的视频画质评测服务。\n\n因此,「度知了」是一个在线问答平台,提供视频画质评测服务。',
'根据提供的上下文信息,「度知了」是一个在线问答平台,提供视频画质评测服务。它基于ITU标准,依托自研的10+项专利技术,支持多端(PC,Android,iOS)评测。该平台旨在帮助用户更好地理解和掌握知识,并提供了一个方便的途径来获取所需的信息。「度知了」已上架各大商店应用市场,安卓端可通过华为应用商店、百度手机助手、小米应用商店、oppo应用商店、vivo应用商店直接搜索「度知了」进行安装。在APP端,用户可以通过快捷创建创建一个评测任务。',
"Based on the new context, the existing answer is still accurate. The 'duzhiliao' in the original answer refers to the online platform 'Du Zhili', which provides video quality evaluation services. It is a multi-platform application (PC, Android, iOS) that uses 10+ self-developed patent technologies based on ITU standards to help users better understand and master knowledge, and provide a convenient way to obtain needed information. The platform has been uploaded to various store application markets, and users can install it through search for 'Du Zhili' on Huawei App Store, Baidu App Store, Xiaomi App Store, OPPO App Store, Vivo App Store. In the app, users can quickly create a review task."
],
'output_text': "Based on the new context, the existing answer is still accurate. The 'duzhiliao' in the original answer refers to the online platform 'Du Zhili', which provides video quality evaluation services. It is a multi-platform application (PC, Android, iOS) that uses 10+ self-developed patent technologies based on ITU standards to help users better understand and master knowledge, and provide a convenient way to obtain needed information. The platform has been uploaded to various store application markets, and users can install it through search for 'Du Zhili' on Huawei App Store, Baidu App Store, Xiaomi App Store, OPPO App Store, Vivo App Store. In the app, users can quickly create a review task."
}为了显示 RAG 的优点,我们可以利用 列表 10.14 所示的代码向 LLM 问同样的问题:
res = chain.run(name="小明", user_input="什么是度知了?")
print(res)
# ['度知了是一款智能问答产品,它能够理解并回答问题,提供信息和建议,主要应用在搜索、智能问答、智能语音交互等领域。\n\n度知了运用了文心大模型的能力,涵盖了海量数据,可以更好地理解和回答各种各样的问题。文心大模型是中国的一个大规模语言模型,它可以用于各种自然语言处理任务,包括文本分类、问答、文本摘要等。']12.6 RetrievalQA
使用 RetrievalQA 也可以实现 列表 12.11 同样的功能,并且代码整体会更简洁。
列表 12.12: 基于 RetrievalQA 和 Milvus 的 RAG
#encoding: utf-8
"""
@discribe: example for RetrivalQA.
@author: wangwei1237@gmail.com
"""
from langchain.chat_models import ErnieBotChat
from langchain.embeddings import QianfanEmbeddingsEndpoint
from langchain.vectorstores import Milvus
from langchain.chains import RetrievalQA
from langchain.vectorstores.base import VectorStoreRetriever
from retrieval_prompt import PROMPT_SELECTOR
retriever = VectorStoreRetriever(vectorstore=Milvus(embedding_function=QianfanEmbeddingsEndpoint(),
1 connection_args={"host": "127.0.0.1", "port": "8081"}))
llm = ErnieBotChat()
2prompt = PROMPT_SELECTOR.get_prompt(llm)
3retrievalQA = RetrievalQA.from_llm(llm=llm, prompt=prompt, retriever=retriever)
query = "什么是度知了?"
4res = retrievalQA.run(query)
print(res)- 1
- 使用 Milvus 初始化向量检索器
- 2
- 因为文心对 MessageList 的限制,所以此处要重写 Prompt,否则执行时会报 Message 类型错误。具体提示词的修改可以参考:列表 12.13。
- 3
- 使用向量检索器初始化 RetrievalQA 实例
- 4
- 执行 RAG 检索并提炼最终结果
列表 12.13: RetrievalQA 的提示词
# flake8: noqa
"""
@discribe: prompt for test_retrievalQA.py.
@author: wangwei1237@gmail.com
"""
from langchain.chains.prompt_selector import ConditionalPromptSelector, is_chat_model
from langchain.prompts import PromptTemplate
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
AIMessagePromptTemplate,
)
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Helpful Answer:"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
system_template = """Use the following pieces of context to answer the users question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
----------------
{context}"""
messages = [
1 HumanMessagePromptTemplate.from_template(system_template),
2 AIMessagePromptTemplate.from_template("OK!"),
HumanMessagePromptTemplate.from_template("{question}"),
]
CHAT_PROMPT = ChatPromptTemplate.from_messages(messages)
PROMPT_SELECTOR = ConditionalPromptSelector(
default_prompt=PROMPT, conditionals=[(is_chat_model, CHAT_PROMPT)]
)- 1
-
修改
SystemMessagePromptTemplate为HumanMessagePromptTemplate。 - 2
-
增加一条
AIMessagePromptTemplate消息。
列表 12.12 的运行结果如下所示:
度知了是一款视频画质评测服务,基于ITU标准,依托自研的10+项专利技术,支持多端(PC、Android、iOS)评测,提供画质评测工具。