8 Agent
LLM 也会有 阿克琉斯之踵。
8.1 阿克琉斯之踵
虽然 LLM 非常强大,但在某些方面,与“最简单”的计算机程序的能力相比,LLM 并没有表现的更好,例如在 计算 和 搜索 这些计算机比较擅长的场景下,LLM 的表现却却很吃力。
列表 8.1: 文心大模型的计算能力测试
#encoding: utf-8
"""
@discribe: example for Ernie's calculate ability.
@author: wangwei1237@gmail.com
"""
from langchain.chat_models import ErnieBotChat
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
template = ChatPromptTemplate.from_messages([
("user", "你是一个能力非凡的人工智能机器人"),
("assistant", "你好~"),
("user", "{user_input}"),
])
chat = ErnieBotChat()
chain = LLMChain(llm=chat, prompt=template)
res = chain.run(user_input="4.1*7.9=?")
print(res)列表 8.1 的执行结果如下:
['4.1乘以7.9等于31.79。']但实际上,\(4.1 * 7.9 = 32.39\),很明显,文心给出了错误的结果。

计算机程序(例如 python 的 mumexpr 库)可以轻而易举的处理这种简单的计算,甚至处理比这更复杂的计算也不在话下。但是,面对这些计算,LLM 有时候却显得力不从心。
在 章节 7 中,我们提到,使用 RAG 可以解决训练数据的时效性问题、LLM 的幻觉问题、专有数据的安全性问题等问题,但是对于 列表 8.1 所示的问题,我们将如何解决?
为了让 LLM 能更好的为我们赋能,我们必须解决这个问题,而接下来要介绍的 Agent 就是一种比较好的解决方案。
利用 Agent,我们不但可以解决如上提到的 计算 的问题,我们还可以解决更多的问题。在我看来,Agent 可以解锁 LLM 的能力限制,让 LLM 具备无穷的力量,实现我们难以想象的事情。
8.2 什么是 Agent
在日常生活中,我们解决问题也不是仅依靠我们自己的能力,我们也会使用计算器进行数学计算,我们也会 百度一下 以获取相关信息,君子性非异也善假于物也。同样,Agent 使得 LLM 可以像人一样做同样的事情。
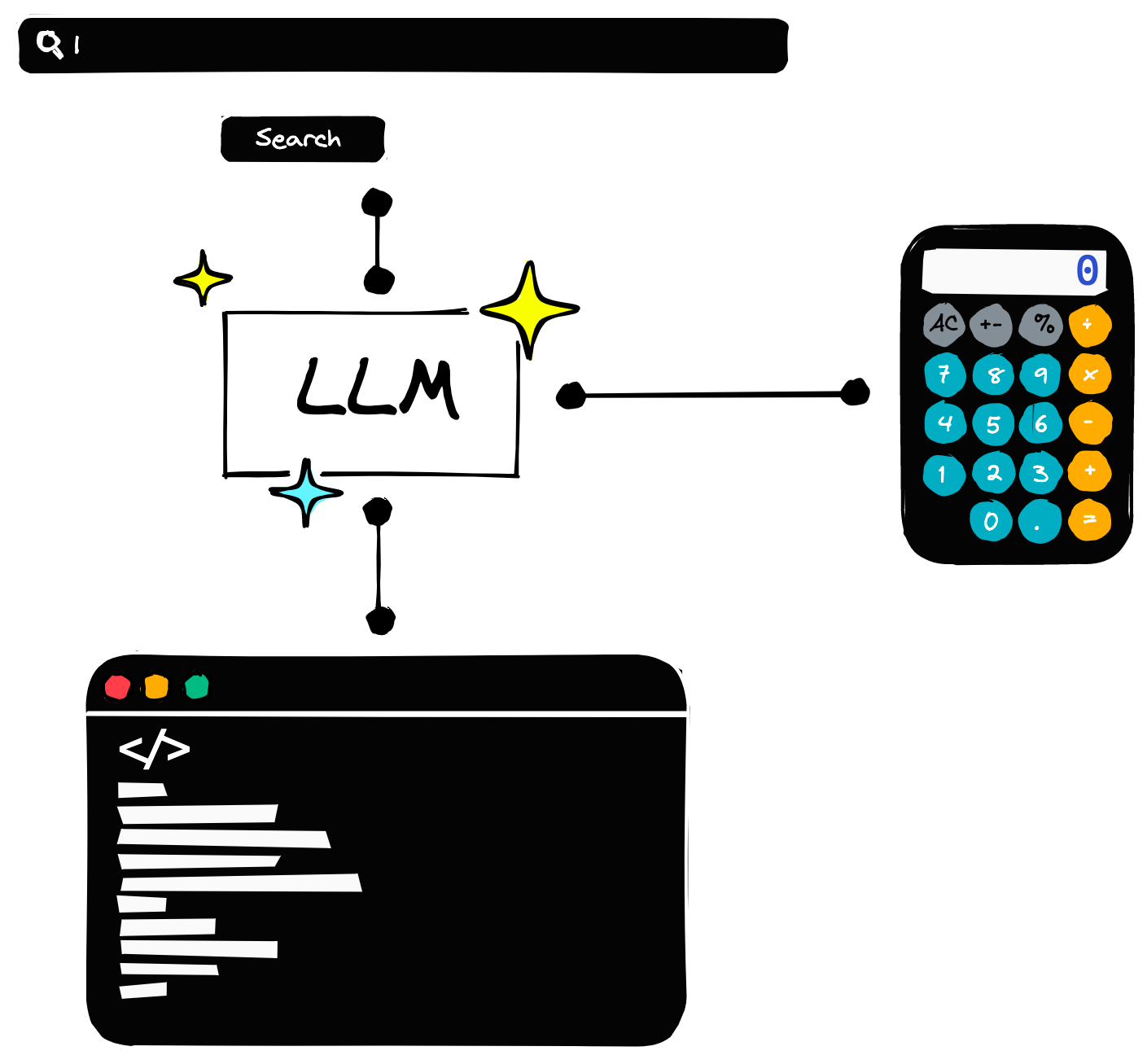
从本质上讲,Agent 是一种特殊的 LLM,这种特殊的 LLM 的特殊性在于它可以使用各种外部工具来完成我们给定的操作。
与我们使用外部工具完成任务一样:
- 我们首先会对任务进行思考
- 然后判断我们有哪些工具可用
- 接下来再选择一种我们可用的工具来实施行动
- 然后我们会观察行动结果以判断如何采取下一步的行动
- 我们会重复 1-4 这个过程,直到我们认为我们完成了给定的任务
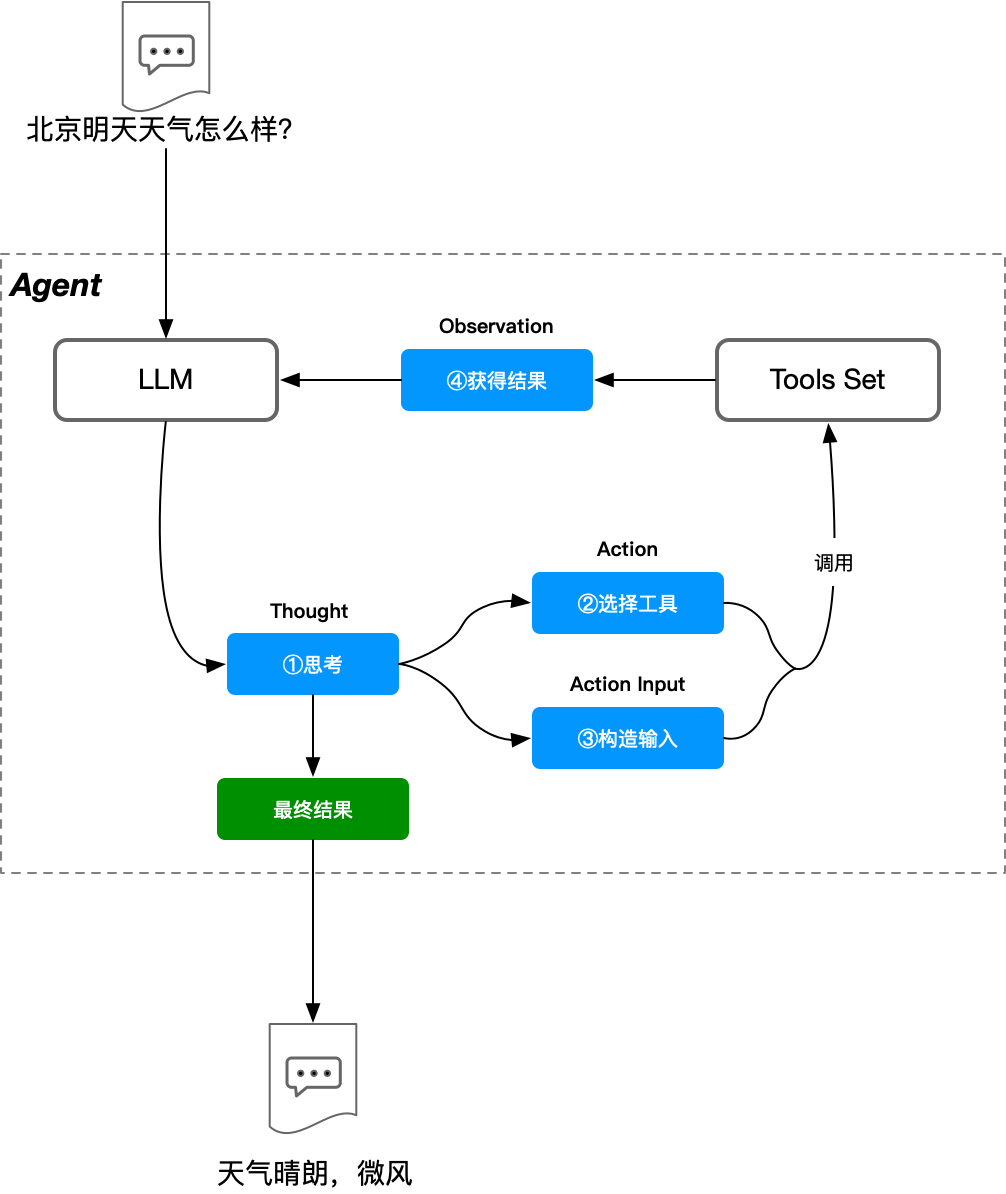
如 图 8.3 所示,虽然 Agent 本质上是 LLM,但是其包含的 Thought 和 Tools Set 将 Agent 和 LLM 区别开来,并且这种逐步思考的方式也使得 LLM 可以通过多次推理或多次使用工具来获取更好的结果。
根据 B 站 UP 主发布的视频:作为一款优秀的 Agent,AutoGPT 可以实现自己查询文献、学习文献,并最终完成给定论文题目写作的整个过程,而整个过程中出了最开始需要给 AutoGPT 发布任务外,其他环节则全部由 AutoGPT 自动完成。
8.3 ReAct 模式
此处的 ReAct 既不是软件设计模式中的 reactor 模式1,也不是 Meta 公司开发的前端开发框架 react2,而是 Yao 等人在 [2],[5] 中提出的:把 Reasoning 和 Action 与语言模型结合起来的通用范式,以解决各种语言推理和决策任务。
ReAct 使 LLM 能够以交错的方式生成 reasoning traces 和 text actions,ReAct 可以从上下文中进行推理并提取有用的信息来进行后续的 reasoning 和 action,从而影响模型的内部状态。正如 [2] 说述,ReAct 将推理阶段和行动阶段进行有效的结合,进一步提升了 LLM 的性能。
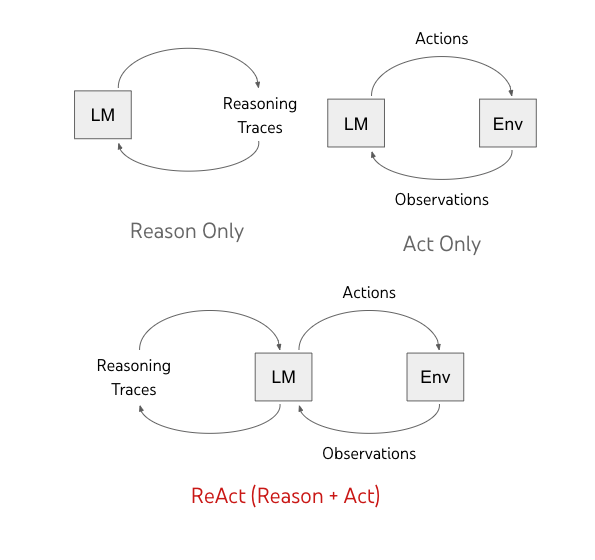
实际上,和 图 8.3 所示的流程是一致的。
ReAct 也称为 Action Agent,在 ReAct 模式系下,Agent 的下一步动作由之前的输出来决定,其本质是对 Prompt 进行优化的结果,一般可以用于规模较小的任务。
8.4 PlanAndExecute 模式
如前所述,Action Agent 适用于规模较小的任务。当任务规模较大,而任务的解决又高度依赖 Agent 来驱动并完成时,Action Agent 就开始变得捉襟见肘。
我们即希望 Agent 能够处理更加复杂的任务,又希望 Agent 具备较高的稳定性和可靠性。这中既要又要的目标导致 Agent 的提示词变得越来越大,越来越复杂。
- 为了解决更复杂的任务,我们需要更多的工具和推理步骤,这会导致 Agent 的提示词中包含了过多的历史推理信息
- 同时,为了提升 Agent 的可靠性,需要不断的优化/增加 Tool 的描述,以便 LLM 可以选择正确的工具
在这种背景下,PlanAndExecute 模式应运而生。PlanAndExecute 将 计划(plan) 与 执行(execute) 分离开来。
在 PlanAndExecute 模式下,计划 由一个 LLM 来驱动生成,而 执行 则可以由另外的 Agent 来完成:
- 首先,使用一个 LLM 创建一个用于解决当前请求的、具有明确步骤的计划。
- 然后,使用传统的 Action Agent 来解决每个步骤。
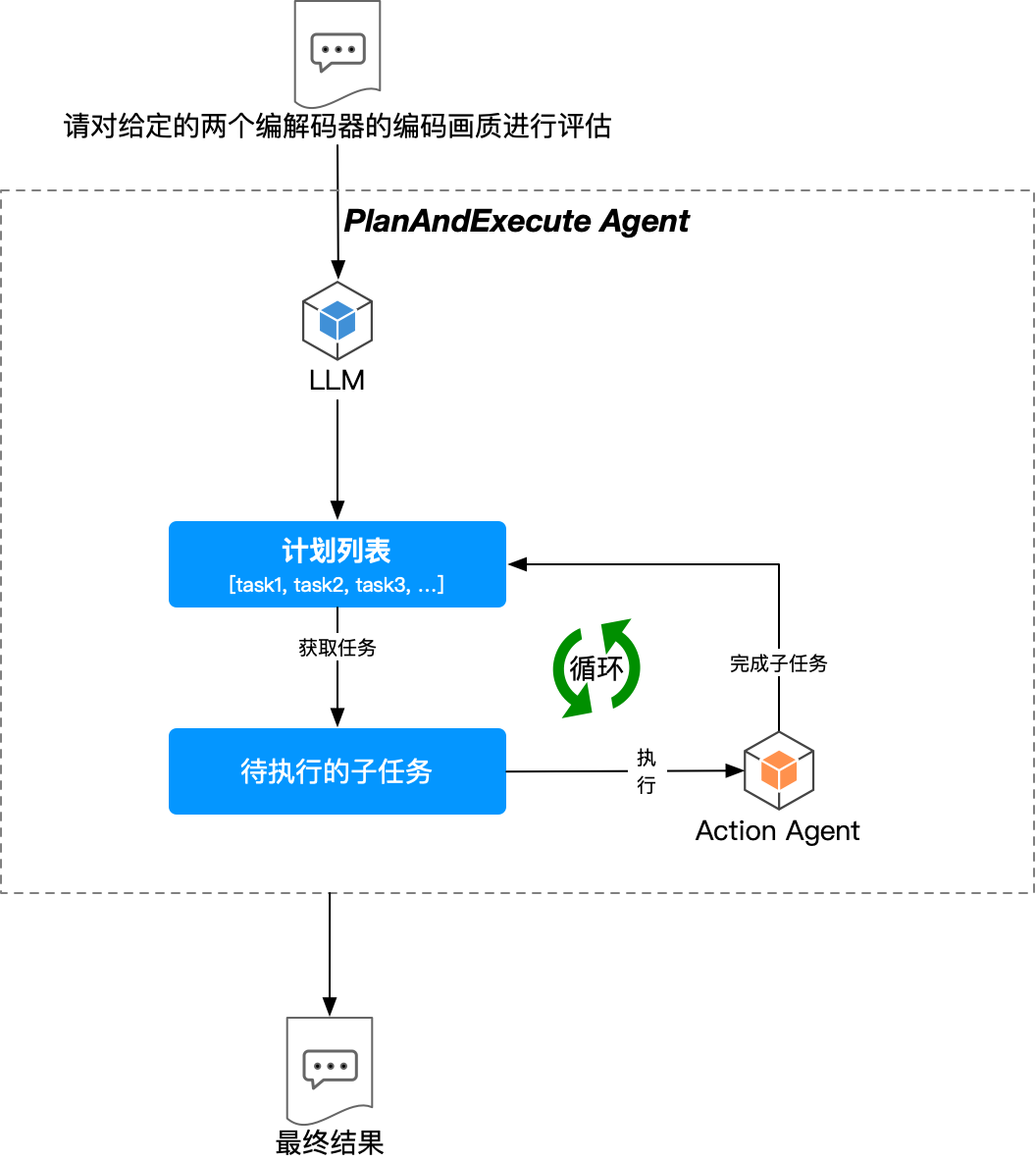
目前,BabyAGI 也采用了类似的模式3,更多关于 PlanAndExecute 模式的底层细节,可以参考 [4]。
该模式下,Agent 将大型任务分解为较小的、可管理的子目标,从而可以高效处理复杂任务。
这种方式可以通过 计划 让 LLM 更加“按部就班”,更加可靠。但是其代价在于,这种方法需要更多的 LLM 交互,也必然具有更高的延迟。4
8.5 Multi-Agent
到现在为止,我们所讲的 Agent 都是 Single-Agent,也就是说我们仅在这个单独的 Agent 中(没有和其他的 Agent 交互),就完成了用户提出的任务。在 [1] 中提到,Multi-Agent 是分布式 AI 领域的一个分支,强调在不同的 Agent 之间进行协作以完成用户的任务,这个时候的 Multi-Agent 主要存在于强化学习和博弈论(game theory) 的相关研究中。[3] 提出了一种新的框架,通过利用 Multi Agent 系统的能力来增强大型语言模型 LLM 的能力,在这个新的框架中,作者引入了一个协作环境,在这个环境中,Multi Agent 组件(每个组件具有独特的属性和角色,可以由不同的 LLM 来驱动)协同工作,从而可以更高效、更有效地处理复杂的任务。
从本质上讲,Multi LLM Agent 是涉及到多个 LLM 驱动的 Agent 协同工作的融合体。与传统的 Single Agent 不同,Multi Agent 系统由各种 AI Agent 组成,每个 Agent 专门研究不同的领域,有助于全面解决问题。这种协作、协同效应产生了更细致和有效的解决方案。
正如 图 8.6 所示,Multi Agent 系统可以通过不同 Agent 之间的协作来完成更为复杂的事情。
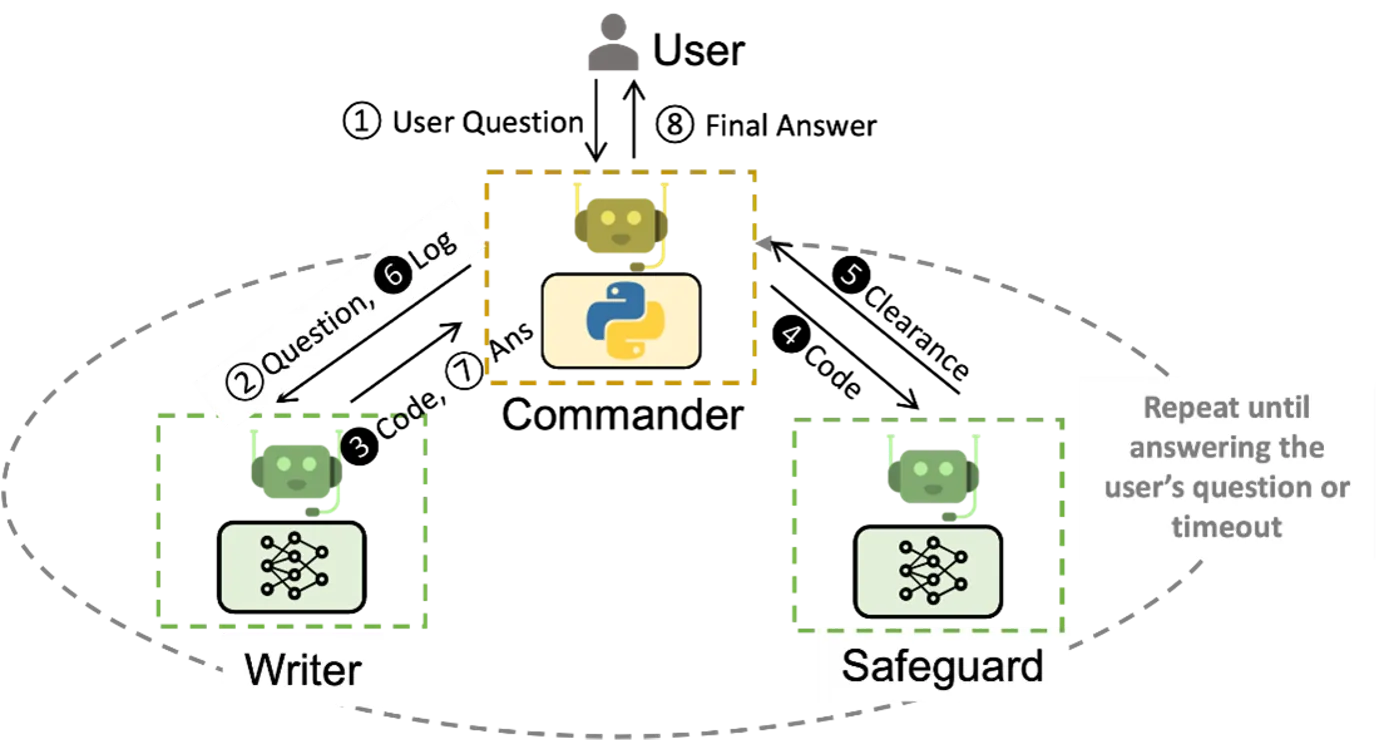
Multi Agent 的优势如下6:
- 专业技能更强:在 Multi Agent 系统中,每个 Agent 都拥有各自领域的专业知识,使其能够提供深入、准确的响应。这种专业知识的广度确保了所生成的解决方案是全面和知情的。
- 问题解决能力更强:复杂的问题往往需要采用不同层面的、综合的方法,Multi Agent 通过整合各个 Agent 的集体智慧,通过利用不同 Agent 各自的优势,以提供单 LLM 或者 单 Agent 难以解决的问题。正所谓:众人晒柴火焰高。
- 稳定性更高:冗余和可靠性是人工智能驱动解决方案的关键因素。从架构上讲,Multi Agent 降低了单点故障的风险,如果一个 Agent 遇到问题或限制,其他 Agent 则可以介入,以确保整体系统的稳定性。
- 适应性更好:在一个充满活力的世界里,适应性至关重要。Multi Agent 可以随着时间的推移而发展,新的 Agent 可以无缝集成以应对新出现的挑战。